
1 Introduction
Given the importance of the historical and cultural value of Balinese lontar (palm leaf manuscript) collections, efforts to save these ancient lontars have begun through various processes of digitization [1]. Unfortunately, efforts to save manuscript collections are not always accompanied by comprehensive efforts to disseminate the contents of the lontars to the public. Meanwhile, lontar collections may contain invaluable knowledge regarding all aspects of life and local Balinese culture since ancient times [2-4].
Apart from religious factors and the sacredness of lontars, one of the challenges faced in efforts to disseminate the knowledge stored in lontar collections is the community's limited ability to read the Balinese script used in lontars. Not many
ordinary people are able to read the text in lontars [2,5]. The Balinese today still use the Balinese language in daily life, but no longer use Balinese script. Nowadays, the younger generations are less familiar with writings in Balinese script. This makes people reluctant to try to explore the contents of lontars in order to read and understand the valuable knowledge in it. It is very difficult for people to find the desired lontar content from existing lontar collections, even when they have been digitized. In order to give added value to digitized lontar collections, an automatic word indexation system for lontar collections is needed. The automatic word indexation system is expected to be able to assist the public in finding keywords regarding the content of lontars. The results of this indexation system will help people in finding the content they are looking for in lontars.
This paper proposes a preliminary scheme towards the development of an automatic word indexation system for Balinese lontar collections. For this initial proposal a word indexation system scheme was built that has two sub modules: one for patch image extraction of text areas in lontars [3,4] and one for word image transliteration. By combining these two modules, it was hoped that the proposed indexation system would be able to detect text, extract word patch images, transliterate word images in Balinese script into text in Latin/Roman script, and index the text based on keywords. To the best of our knowledge such a word indexation system for lontar collections has not been proposed previously. The main contribution of this work lies in the fact that this system is supported through our in-depth study results on various components of the document image analysis (DIA) system for lontar collections [1-7].
In the next section of this paper we will briefly explain Balinese lontar collections. A detailed description of the proposed scheme and methods is provided in Section 3. Section 4 presents the experimental tests results. And finally, the conclusions and discussions for future works are given in Section 5.
2 Lontar Collections
In Bali, there are two main museums that house lontar collections: Gedong Kirtya Museum in Singaraja and Museum Bali in Denpasar. However, it is believed that the largest lontar collections are in possession of Balinese families, which have been handed down from generation to generation as family heritage. Balinese lontars are written in Balinese script, which is a derivative of the Brahmi script from India, Old Javanese or Kawi, mixed with Sanskrit. Balinese script is an alpha syllabic script, where each glyph represents a syllable. As an alpha syllabic script from Southeast Asia, Balinese script is considered a complex writing system. In general, the sound of speech in a syllable changes according to certain phonological rules [8]. In such cases, simply using a glyph recognizer (OCR) is
not sufficient. Therefore, a transliteration system has to be developed to assist the indexation system [9].
One of the projects related to digitizing Balinese lontar collections is the AMADI (Ancient Manuscript Digitization and Indexation) project [1]. This project not only aims to digitize lontars, but is also building a complete document image analysis (DIA) system for the collection. Through this project, a standard and valid dataset has been published that can be used for research on the development of the DIA system for lontars. The 399 digital image samples of lontars in this project were collected from 23 different lontar collections, from 5 different locations (areas) in Bali, so they are very representative of the different types of lontar handwriting from different writers as well as of the variation in the material condition of the lontars. Although many components of the DIA system for lontars have already been proposed by the AMADI project, several components of the system are still under development. Research on the DIA system for lontars is currently being continued by the EpsiLont (Electronic Pattern Analysis for Lontar) project [10].
3 Proposed Scheme and Methods
As mentioned above, the proposed word indexation scheme for lontar collections consists of two sub modules: a sub module for image patch extraction of text areas and a sub module for word image transliteration (Figure 1).
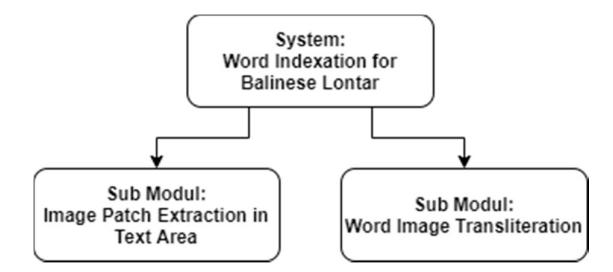
Figure 1 General architecture of the proposed word indexation system for lontar collections.
3.1 Image Patch Extraction of Text Areas
The sub module for image patch extraction of text areas is tasked with extracting image patches from lontar pages with the aim of being able to extract text from lontar images with the minimum number of patches possible. Parts of the lontar page that do not contain text, or parts of patch areas that do not cover the lontar text properly are eliminated in order to reduce the number of patches. A large number of patches will make the lontar indexation process too long, while incomplete patch extraction will cause some areas of the text in the lontar to not be acquired as patch images.
To perform the process of image patch extraction of text areas of lontars there are two steps that must be taken (Figure 2). First, the parts of the lontar that contain text are detected. Then in the second step these text areas are cropped or extracted into image patches that are close to the size of a word.
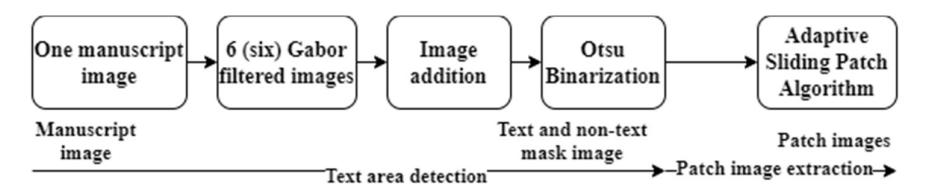
Figure 2 Process of image patch extraction of text areas.
3.1.1 First step: text area detection with Gabor filter
Writing strokes on the lontar leaf constitute a text area in the lontar image, containing orientation and frequency information. The textures of the writing from different lontar writers and different degraded conditions of lontar pages challenge the effort to detect text areas in lontars. Moreover, the layout of written text on lontar pages also varies. Most lontars contain full text from left to right in four lines of text (Figure 3(a)). However, there are also lontar pages that contain text and images or graphical symbols (Figure 3(b)). In addition, there are also lontar pages with text writing in scattered positions separated by large empty areas (Figure 3(c)) and there are also writing layouts in lontars that resemble a table with separate columns (Figure 3(d)).
To detect the parts of a lontar that contain text, the proposed technique uses Gabor filters to provide initial information about the presence of text texture in the lontar image. A Gabor filter is a texture detection filter that is capable of performing texture feature extraction at different orientations and frequencies [3,5]. Gabor filters can be applied with several different combinations and variation of parameters to detect textures with different orientations and frequencies. The parameters of a Gabor filter include orientation, wavelength, aspect ratio, and bandwidth. Given the various possible combinations of these parameters, we can construct different sets of Gabor filters to be applied as a bank of filters. This will strengthen the ability of Gabor filtering to simultaneously detect different types of textures contained in one image. In this study, we applied a bank of Gabor filters consisting of six filters with six different orientations (0°, 45°, 135°, 180°, 225°, and 315°), with a wavelength value of 8, an aspect ratio of 0.5, and a bandwidth of 1 (Figure 4).

Figure 3 Some variations of text, images, and writing layouts in lontars.

Figure 4 Examples of an original lontar image with six different Gabor filtered images (with a zoomed part).
The six images from the texture detection results of each of the Gabor filters are then added together to obtain texture information values for all directions. The final image from the combined Gabor filter images is then binarized with the Otsu method [11] to obtain a binary image containing text and non-text pixel information as a mask image (Figure 5) for the patch image extraction process.

Figure 5 Final binarized image as mask image for text and non text pixels.
3.1.2 Second step: patch image extraction with the adaptive sliding patch algorithm
After obtaining the mask image to localize text pixels and non-text pixels or text areas on the lontar page, the image patches must be cropped or extracted in a suitable position in relation to the text area. The main challenge in the patch extraction process is the absence of spaces between words in Balinese writing in lontars. Therefore it is impossible to apply a word segmentation method to text from lontars. Another challenge is that text in lontars in the horizontal direction from left to right is not always completely straight. Moreover, the writing of lontars is not always properly guided by a straight line (some are a bit wavy). Imperfections during the capturing process of lontar images can also sometimes make the writing in the lontars appear slightly curved. Under these conditions, the spacing between lines of text in tlontar pages is not regular and straight. To overcome the above challenges, an adaptive sliding patch algorithm is proposed for the extraction of patch images from lontars [3].
In the adaptive sliding patch algorithm, a small window that is close to the size of a word in lontars is moved from left to right and from top to bottom to explore the possibility of finding the correct position in the text area as a patch. In this study, the size of the sliding window used was 300 (width) x 100 (height) pixels. The height of 100 pixels was determined empirically by looking at the average height of one line of text or one word in Balinese writing that contains ascender, base and descender glyphs (30 pixels height x 3 glyph composition in the vertical direction ~90-100 pixels height). Meanwhile, the width of 300 pixels was determined by looking at the results of previous studies, which state that the word recognition rate in lontars is better for longer words. Seeing that the average number of glyphs in one word in lontars is 3 glyphs (3 x 50 pixels width = 150 pixels width), the window width for extracting the patch was determined to be the same as the size of two words (2 x 150 pixels width = 300 pixels width). Thus, it was hoped that there would be a greater chance that a window would be found in which there is a correct word without separating it into two distinct patch
pieces. The movement of the sliding window in the horizontal and vertical directions is carried out as far as 50 pixels. Thus, in the horizontal direction there will be an overlapping area between two consecutive sliding window positions of 250 pixels, while in the vertical direction there will be an overlapping area between two consecutive sliding window positions of 50 pixels. The concept of overlapping patches is carried out to provide more opportunities for extracting precise word positions. The shift of 50 pixels was determined empirically by considering the average size of a glyph in Balinese writing in lontars, which is 50 x 50 pixels.
During the sliding window movement, the algorithm calculates the ratio of text pixels compared to the total number of pixels in patch image R. The value of R indicates if there are enough text pixels in the window to be considered as a correct word patch image (R > 0.1). A second verification will be done by calculating the ratio of text pixels in three different parts of the window: upper part (U), middle part (M), and lower part (L). These three values are used to verify that in this word patch image the text is in a suitable position, which is along the central-medial line of the text (when M > U and M > L). The algorithm will crop and extract the patch image when both conditions are met. Otherwise, the sliding patch movement will be continued by repetitively moving the window 2 pixels in a lower vertical position until a correct word patch image is found. During the searching process in the vertical direction, the horizontal position of the window stays the same. The algorithm is applied to visit and verify all possible patch images on the lontar page (Figures 6 and 7).
Figure 6 Some examples of an original lontar page and the area covered by word patch images (in red).

Figure 7 Some examples of word patch images extracted by the adaptive sliding patch algorithm.
3.2 Word Image Transliteration
After all word patch images have been extracted from the lontar page, the next step is to carry out the transliteration process. Transliteration involves rendering language from one writing system to another writing system. Transliteration helps to index and access manuscript content quickly and efficiently. Several transliteration models have been proposed [12-15]. In the proposed indexation system for lontars, the sub module for word image transliteration performs a direct transliteration process from the patch image data containing Balinese script to Latin/Roman script.
In this study, the word image transliteration sub module was built using the long short-term memory (LSTM) model. In the field of machine learning, LSTM is widely used in sequence analysis problems. The text recognition and transliteration process are common problems that can naturally implement the LSTM model. LSTM has two main advantages: context-sensitive learning and good generalization [16,17]. LSTM has been widely used for text recognition tasks without the use of specific feature extraction methods and language models. The value of image pixels can be sent directly as input to the learning network without the need to segment the training data sequence. The LSTM architecture is known as a generic and language-independent text identifier [18]. LSTM has been used successfully to recognize handwritten as well as printed text [17]. LSTM is a modified RNN architecture. The LSTM network adds multiplicative gates and additive feedback. LSTM can delete unnecessary information in a cell and add new information to be stored in the cell. The backward process of LSTM is the process of back propagation from errors in the output generated by the forward process compared to the target output. The value of learning weights and bias in the LSTM network is updated during the back propagation process using the time algorithm [17].
To build the word image transliteration sub module in this study, the word segment image dataset from AMADI_LontarSet [1] was used for the training process. The AMADI_LontarSet contains a dataset for the transliteration of word segment images from Balinese lontars, which consists of 15,022-word segment images from 130 pages of Balinese lontars as training data and 10,475-word segment images from 100 pages of Balinese lontars as test data. Each word segment image in the dataset contains transliterated text as ground truth data (Figure 8). In this study, we used the default parameters, i.e. batchSize = 50, imgSize = (128, 32), maxTextLen = 32, numHidden = 256 for the LSTM network.

Figure 8 Word segment images for transliteration in AMADI_LontarSet.
4 Results and Discussion
In this section, first the dataset and the evaluation methods used for the experimental test of the word indexing system is presented. The experimental test results are displayed quantitatively, followed by some discussion.
4.1 Dataset
In this study, 100 lontar images from the AMADI_LontarSet [1] were used to measure the performance of the proposed word indexation system. The 100 lontar
images were part of the test set from the AMADI_LontarSet that was used for the word spotting challenge in the 2016 ICFHR competition [19].
4.2 Evaluation Method
To evaluate the performance of the word indexation system, we measured the values of recall and precision. In the context of word indexation, recall is the percentage of indexed 'relevant words' from the system compared to the total number of indexed words in the ground truth data for one lontar page. Precision is the percentage of indexed 'relevant words' from the system compared to the total number of indexed words from the system for one lontar page. The term 'relevant words' is defined in two conditions as follows: an indexed word from the system is considered a 'relevant word' firstly if the transliteration text of that indexed word contains at least one transliteration text from all possible indexed words from the ground truth data, and secondly if the position of the matching indexed word patch image overlaps with the position of the respective indexed word patch image in the ground truth data (Figure 9).
Figure 9 An example of indexed 'relevant words', where the green rectangle is the word patch image extracted from the system with the transliteration text of 'kangurukang', while the purple rectangle is the word segment image in the ground truth data with the transliteration text of 'ngurukang'. Both overlap and 'ngurukang' is contained in 'kangurukang'.
4.3 Experimental Results
As an example, Table 1 shows 20 indexed 'relevant words' extracted by the proposed system from one lontar page. For each ground truth word data it consists of its transliterated text and its coordinate (position) of the ground truth word segment (patch) in the lontar image. For each indexed word extracted by the proposed system, it also consists of the transliterated text and the coordinate (position) of the indexed word segment (patch) in the lontar image. Both the transliterated text and the segment position are compared to decide whether a ground truth word and an indexed word are relevant.
Table 1 Examples of 20 indexed 'relevant words' from one lontar page.
Table 2 shows the value of minimum, maximum, and average recall and precision of the word indexation results for each different lontar collection from a total of 100 lontar pages.
Table 2 Minimum, maximum, and average recall and precision of word indexation results for each lontar collection.
| Lontar Collection | Nb | Min | Max | Avg | Min | Max | Avg Precision |
|---|---|---|---|---|---|---|---|
| Pages | Recall | Recall | Recall | Precision | Precision | Avg Frecision | |
| Bangli | 8 | 10.20 | 30.61 | 17.97 | 7.47 | 32.14 | 20.72 |
| IIA-10-1534 | 4 | 27.22 | 36.59 | 32.94 | 25.83 | 36.01 | 32.70 |
| IIA-5-789 | 4 | 34.53 | 42.75 | 36.84 | 24.20 | 36.96 | 30.46 |
| IIB-2-180 | 3 | 20.00 | 41.62 | 29.42 | 1.47 | 42.97 | 22.38 |
| IIIB-12-306 | 2 | 10.00 | 34.87 | 22.44 | 0.70 | 28.36 | 14.53 |
| IIIB-42-1526 | 4 | 25.00 | 36.54 | 29.30 | 2.38 | 28.67 | 20.82 |
| IIIB-45-2296 | 4 | 16.67 | 33.33 | 26.37 | 0.97 | 22.95 | 14.66 |
| IIIC-19-1293 | 2 | 18.92 | 25.23 | 22.08 | 9.04 | 16.67 | 12.86 |
| IIIC-20-1397 | 4 | 14.29 | 30.05 | 21.43 | 1.75 | 22.25 | 14.06 |
| IIIC-23-1506 | 3 | 23.08 | 25.68 | 24.59 | 9.05 | 19.95 | 12.76 |
| IIIC-24-1641 | 3 | 28.46 | 37.80 | 33.20 | 18.78 | 24.15 | 20.86 |
| JG-01 | 5 | 17.39 | 22.54 | 20.39 | 13.51 | 22.40 | 18.42 |
| JG-02 | 4 | 15.38 | 25.93 | 21.38 | 12.37 | 23.40 | 16.66 |
| JG-03 | 5 | 11.70 | 16.48 | 13.67 | 7.22 | 14.23 | 10.01 |
| JG-04 | 4 | 13.16 | 27.27 | 20.18 | 5.00 | 11.79 | 8.58 |
| JG-05 | 2 | 7.91 | 12.50 | 10.21 | 4.20 | 13.52 | 8.86 |
| JG-06 | 1 | 12.64 | 12.64 | 12.64 | 6.38 | 6.38 | 6.38 |
| JG-07 | 4 | 6.78 | 12.31 | 9.79 | 5.62 | 13.33 | 10.24 |
| MB-AdiParwa(Purana)-5338.2-IV.a | 10 | 24.35 | 44.22 | 33.82 | 17.63 | 43.75 | 27.71 |
| MB-ArjunaWiwaha-GrantangBasaII | 8 | 24.19 | 39.34 | 32.87 | 12.71 | 23.74 | 20.39 |
| MB-TaruPramana | 11 | 21.25 | 47.14 | 35.16 | 8.77 | 31.91 | 20.14 |
| WN | 5 | 6.49 | 21.95 | 13.59 | 2.11 | 13.12 | 7.95 |
| Total Number of Pages | 100 |
Figure 10 shows an example of the visualization of indexed 'relevant words' extracted from the system and the corresponding indexed 'relevant words' from the ground truth data of one lontar page.

Figure 10 Visualization of indexed 'relevant words' extracted by the system (in green) and the corresponding indexed 'relevant words' from the ground truth data (in purple) of one lontar page.
4.4 Discussion
It can be seen that the image patch extraction of text areas process succeeded in optimally detecting the text areas (Figure 6) and extracting the patch image at a suitable position (Figure 7). The number of extracted patch images was not too high, while still being able to cover all text areas in the lontar. Quantitatively, for some lontar collections the maximum value of recall and precision reached more than 40%, for example the IIB-2-180 collection and the MB-AdiParwa(Purana)- 5338.2-IV.a collection. Both collections are from a museum so they are not severely damaged. Meanwhile, there are lontar collections that have very low average recall and precision values, for example some collections of JG and the collection of WN. These collections are owned by private families and are more severely damaged. This gives a higher level of difficulty to the word indexation process.
In general, the precision value was smaller than the recall value because the precision value was calculated based on the total number of patch images extracted by the system. The total number of patch images was higher than the number of words in the ground truth data because the patch images were extracted in overlapping conditions. Although the performance of this word indexation system was not too high based on the recall and precision values, the ability of the system to at least successfully extract between 20% and 40% of the keywords is considered good. The main challenge in developing a word indexation system for lontars is the absence of spaces between words in lontar text. This makes it very important to do the word patch extraction stage optimally. Without the spatial information between words it is impossible to very precisely segment the locations of words in lontars. The proposed scheme in this paper seeks to provide optimal solutions to overcome this challenge. However, the extraction results of word segments do not always cover a word very precisely, so the indexation results of the words are not very accurate either. However, the proposed scheme
provides a promising method to index a fair number of words from lontars. The results of the indexation of several keywords from a lontar can at least provide an initial description for prospective readers about the content in the lontar collection or to find in which lontar collection certain keywords may be found.
5 Conclusion and Future Works
In this paper, a preliminary scheme towards the development of an automatic word indexation system for Balinese lontar collections is proposed. This scheme is composed of a sub module for patch image extraction for text areas and a sub module for word image transliteration. Based on the experimental results, the proposed system was unable to achieve high recall and precision values, but the word indexation scheme performed well by finding up to 20% to 30% of the lontar keywords. The results can be used to at least help the community in searching or knowing the contents of lontars based on keywords. In a future work, a more complete scheme for combining the transliteration engine and the word spotting engine for indexation of lontars will be analyzed.
Acknowledgement
This research was financially supported by Skema Penelitian Dasar Unggulan Perguruan Tinggi (PDUPT) DRPM DIKTI 2020.