
1 Introduction
Cancer is caused by abnormal cells that grow and spread out of control and can cause death when they are not diagnosed [1]. Areas of the body that are exposed to the most ultraviolet (UV) radiation are where it commonly shows up. For instance, the chance of acquiring skin cancer rises when parts of the body are frequently exposed to UV radiation and direct sunlight, such as the face, neck, arms, and legs. The DNA in skin cells can be damaged over time by excessive UV radiation exposure, which can result in the growth of malignant cells. These body parts are particularly susceptible to the damaging effects of UV radiation, making them frequent locations for the growth of skin cancers such as melanoma. There are three categories of skin cancer: melanoma, basal cell carcinoma, and squamous cell carcinoma [2]. One of the most dangerous types of skin cancer is melanoma, which arises from melanin-producing melanocyte cells. Recent predictions indicated that the number of deaths caused by melanoma skin cancer in the United States in 2023 would be considerably greater for men than for women [3].
Early identification of skin cancer is critical for future therapies that can halt serious lesions, according to research that showed that those who find melanoma early have a survival probability of over 90% [4-6]. Dermoscopy is a significant technique for increasing diagnosis accuracy and reducing skin cancer mortality. By visual examination, dermatologists analyze almost all globally produced dermascopic images, which requires a high level of knowledge and effort, is timeconsuming, and is susceptible to operator bias. Researchers are gradually investigating computer-aided diagnosis to help dermatologists avoid these issues while simultaneously enhancing diagnostic performance, effectiveness, and reliability [7].
Even for dermoscopy images, melanoma and non-melanoma lesions exhibit a significant degree of visual resemblance. In addition to the presence of artifacts and unclear borders, obstacles such as hairs and veins make skin lesion diagnosis more difficult. Figure 1 shows some infected skin images that illustrate the problems.
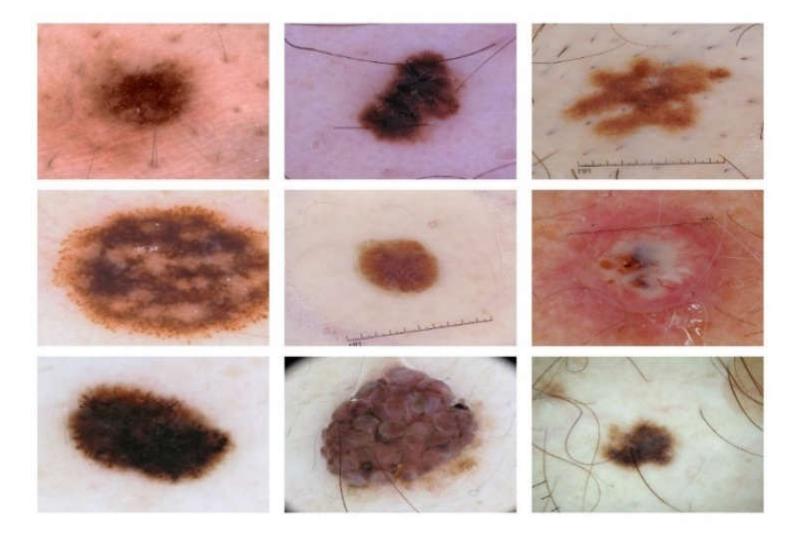
Figure 1 Sample dataset of skin lesions captured in dermoscopy images.
The two most challenging processes are segmentation and feature extraction [8- 10]. Several current methods simply skip the segmentation process, resulting in high misclassification rates. Images have trained deep models that incorporate both lesions and backgrounds, leading to an elevated false-positive rate. This means that the models may incorrectly classify normal skin regions as lesions, leading to potential false alarms and unnecessary interventions. To mitigate this issue, it is crucial to develop segmentation models that can accurately differentiate between skin lesions and background regions. Similarly, when the entire feature vector generates a strong correlation factor between features, the effects become unavoidable in the later stages of classification.
Despite extensive study on melanoma segmentation, establishing accurate and efficient melanoma localization remains a difficult endeavor because of the great variability found in the shape, pigmentation, and size of cutaneous nevi. In this paper, we propose a deep learning model for segmenting skin lesions. It is named Dilated DenseUNet-169 with Copy and Concatenation Attention Block (CCAB). DenseNet-169 is characterized by its 169-layer structure. It is extensively employed in deep learning for classification problems. It possesses much fewer trainable parameters in comparison to other DenseNet designs that have fewer layers. The key contributions of this research are:
- 1. We propose an enhanced UNet technique for key point extraction called Dilated DenseUNet-169 to increase its segmentation power.
- 2. We propose copy and concatenation attention (CCA-UNET) for strong feature computing.
- 3. We present a model consisting of an encoder for capturing plentiful features and a decoder for fusing these features in order to generate feature maps.
- 4. We employ dilated convolution to enhance the kernels' receptivity.
The proposed method uses bypass connections with the encoder and decoder to compel the model to explore low-level features that feedforward would otherwise overlook. On numerous assessment measures from the ISIC 2017 dataset, the suggested model delivered cutting-edge performance.
2 Literature Review
In Hurtado & Reales [11], the authors presented a novel method for classifying skin cancer using photos taken with standard cameras and explored the impact of smoothing bootstrapping on the results after expanding the initial dataset. With an accuracy of 87.1%, an artificial neural network with data augmentation provided the best outcomes and a more balanced classifier.
In order to categorize skin cancer and decide whether it is melanoma, basal cell carcinoma, or squamous cell carcinoma, Chin, et al. [12] used a hybrid
convolutional neural network and an autoregressive integrated moving average model. Chin, et al.[12] trained the model and found it to provide 92.25% accuracy, despite the requirement for more accuracy. Meanwhile, Abd, et al. [13] advocated segmenting artificial bee colonies (ABCs). The selection method outperformed and effectively neutralized qualities previously disregarded. The study's accuracy was 94.40%.
In Pratiwi, et al.[14], the author presents a method to improve performance in terms of sensitivity, F1-score, accuracy, precision, and specificity. The ensemble learning strategy in this work integrates three deep convolutional neural network architectures, i.e., Inception DenseNet, ResNet V2, and Inception V3. With 97.73% specificity, 90.12% sensitivity, 85.01% F1-Score, 82.01% precision, and 97.23% accuracy, the suggested model performed well in melanoma classification.
In Shao, et al. [15], the author uses a convolutional neural network with extended attention (CA-Net) and a multiscale feature fusion network (MSF-Net). In order to concentrate on the important regions, a spatial attention mechanism was incorporated via the remaining link to the convolution block. They ran a number of tests on the open data set ISIC2018, achieving a precision of 92.17%. In [16], the authors utilized a multi-scale UNet (MSAU-Net) or a modified UNet for skin lesion segmentation. To be more specific, they enhanced the ordinary UNet by adding an attention mechanism that resembles a hierarchical structure at the network's choke.
3 Methodology
Our proposed work aims to create a fully convolutional network capable of autonomously segmenting skin lesions in dermascopic RGB images of the skin. We use Dilated DenseUNet-169 as the backbone architecture to segment skin lesions. It has two important phases: network training and melanoma mole segmentation.
To train the model, we utilized the International Skin Imaging Collaboration (ISIC) 2017 dataset, which consists of 2,000 dermascopic skin images with manually or semi-automatically annotated ground-truth labels. We divided the dataset into training, validation, and testing sets in an 80:10:10 proportion. During training, we employed transfer learning by initializing the model with weights from a pre-trained model, which facilitated faster convergence and improved performance. We utilized the Adam optimizer with an initial learning rate of 0.0001 and adjusted the learning rate using the reduce LROnPlateau function to optimize the training process.
To improve feature computation and capture relevant information, we introduced CCAB architecture. This attention mechanism filters and highlights important features, enabling the model to focus on relevant regions for segmentation. We evaluated the performance of our proposed model using various metrics, i.e., accuracy, dice coefficient, Jaccard score, recall, and precision. We compared the results with a baseline UNet model and related works to evaluate the improvement in segmentation accuracy that our Dilated DenseUNet-169 model achieved. We selected the DenseUNet architecture with dilated convolution and incorporated CCAB based on their proven effectiveness in image segmentation tasks. Our methodology stems from the need to tackle the unique challenges of melanoma segmentation, utilizing the latest developments in deep learning technology.
3.1 Encoder-Decoder Semantic Segmentation
This section presents Dilated DenseUNet-169, a semantic segmentation network capable of reliably and automatically separating dermascopic skin lesion images. Its architecture is based on UNet [17]. We can break down the proposed dilated, dense UNet-169 architecture into two sections. The first section contains an encoder that takes an input image, generates a high-dimensional feature vector, and aggregates features at multiple levels for feature extraction. It contains input, pooling, and four dense blocks. Following that are sixteen transition blocks that allow for a smooth change from one condition to another.
The purpose of a transition block is to fill the space between different elements, improving the coherence and efficiency of the system as a whole. In general, transition blocks are crucial in many different applications because they guarantee consistency, coherence, and a positive user experience during transitions or shifts between diverse portions. They advocate for the preservation of flow and the avoidance of abrupt transitions. The decoder, on the other hand, uses a high-dimensional feature vector to construct a semantic segmentation mask and decode characteristics that the encoder has collected at various levels. It consists of five decoding blocks. Each block contains upsampling, concatenation, and convolution blocks. Figure 2 presents a representation of the encoder and decoder.
Both encoders and decoders use dilated convolution. This convolution can collect and process images at various resolutions depending on the dilation rate. It regulates the spacing between kernel locations, effectively expanding their receptive field without adding further parameters. As a result, it may be used to introduce a broader context into the system. It is integrated into spatial convolution, which employs a single convolutional kernel to perform lightweight filtering and reduce computing complexity [15].
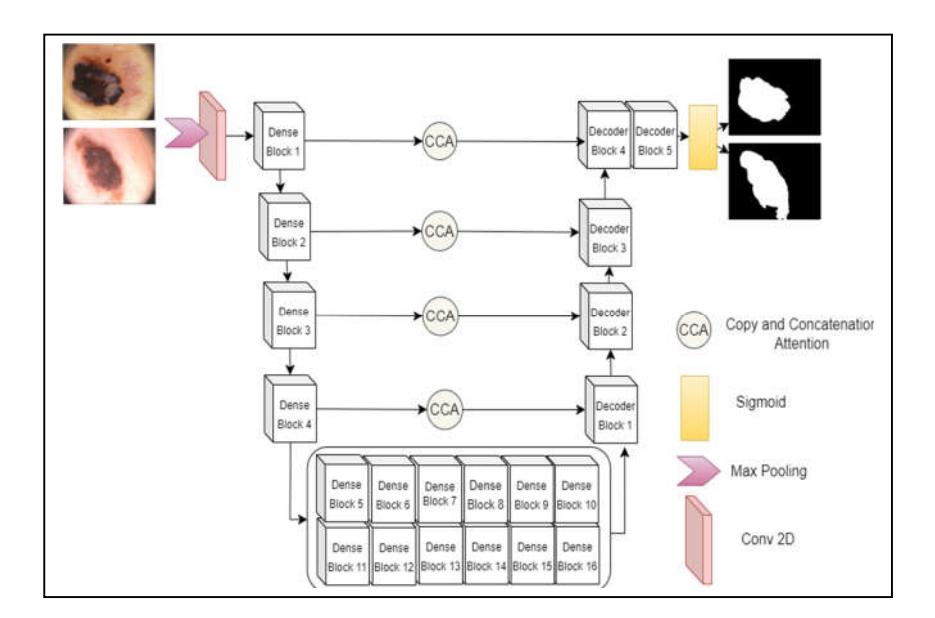
Figure 2 Proposed architecture for dilated convolution semantic segmentation DenseUNet-169.
Skip connections also recover spatial data lost due to pooling at each encoder level. The uniqueness of this study lies in its method, which proposes a dilated density neural network that can segment skin lesions with greater accuracy and robustness than traditional convolutional neural networks while offering new learning capabilities. We modeled the dense blocks and transition blocks after DenseUNet to avoid forcing the suggested network's encoder to learn duplicate features. Figure 3 illustrates both a dense block and a decoder block.
The pooling layer in each encoder block reduces the dimensions of the feature map. As a result, it reduces the number of network calculations and the number of parameters to learn. A convolution layer's feature pooling layer creates a feature map that summarizes the features present in a specific area. The decoder block incorporates an upsampling layer, a simple, weightless layer that doubles the input's dimension and generates output images. The corresponding encoder block then joins the image with its output. To get the final mask, there is a convolution layer with batch normalization and ReLU activation.
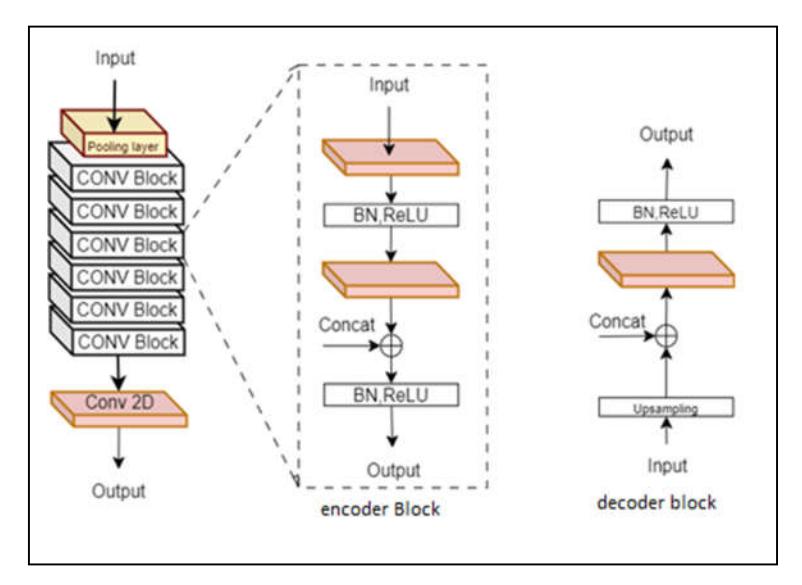
Figure 3 construction of the encoder and decoder blocks.
To increase the network's capacity for using multimodal information thoroughly, we created CCAB to filter the extracted features and eliminate redundant table conv block information. Computer vision frequently employs an attention mechanism. The attention mechanism may increase the weight of discriminative traits while decreasing the weight of irrelevant information, thereby increasing recognition accuracy [15].
To generate an attention map for each step, integrate multi-scale information along the spatial axis. In the channel dimension, we employ global average pooling (GAV), a pooling technique meant to take on the role of fully linked layers in conventional CNNs. The goal is to produce one feature map in the final MLPConv layer for each category that corresponds to the classification problem. Additionally, max-pooling (MP), a pooling procedure that employs the maximum value for patches of a feature map to build a downscaled (pooled) feature map, is another option.
Researchers often use it after a convolutional layer. Then, it concatenates them to generate a feature map with two channels while keeping the height and width constant. The proposed model constructed a spatial attention map for the stage using a dilated convolution with a 3-dilation rate and a 7-kernel size. Finally, as shown in Figure 4, we multiply the generated spatial attention map elementwise by the original map and combine it with the residual information.
The input feature map represents F ∈ R C × H × W with the attention map Ac ∈ R 1 × H × W, and the attention process is expressed in Eq. (1):
\[F = AcF \otimes F \tag{1}\]
⊗ represents element-by-element multiplication; F represents the feature input; R represents the real image; C represents the image length; H represents the image height; W represents the image width; and Ac represents the attention map.
Figure 4 Copy and concatenation attention block architecture.
After applying the common network to each descriptor, Eq. (2) shows how the feature vectors are merged using element-wise summation. Eq. (3) commonly expresses ReLU activation.
\[Ac(f) = Re L U(x)(f7x7([AvgPool(F); MaxPool(F)]))\] (2)
\[Re L U(x) = max(0, x)\] (3)
We have demonstrated the helpfulness of the pooling procedures along the channel axis in identifying informative locations. Here, σ denotes the ReLU function, and f 7 × 7 represents a convolution operation with a filter size of 7 × 7. The dying ReLU problem may occur when neurons that output zero for all inputs (negative and zero values) become inactive during training and stay inactive for the duration of the training procedure. This problem arises because ReLU sets the output to zero for negative inputs, and the gradient of the function is likewise zero for these inputs. Consequently, backpropagation fails to update the weights associated with inactive neurons, thereby halting learning.
3.2 Training
We trained both the proposed model and the baseline UNet model on similar hyper-parameters for a fair comparison. We divided the dataset into 80:10:10 proportions. Thus, training accounted for 80% of the budget, while validation and testing accounted for 10% each. We previously selected a default batch size of 16. We used the Adam optimizer with an initial learning rate of 0.0001. We used the LROnPlateau function to optimize the learning rate, which lowers the learning rate when the validation loss metric no longer improves. When learning stagnates, it waits for 25 epochs to observe any change and then automatically stops the learning process, which reduces the overall training time.
4 Experimentation Results and Discussion
In this section, we address the specific metrics and data set utilized to evaluate the proposed approach's segmentation performance. Furthermore, we conducted multiple tests to assess the strategy in a variety of ways and demonstrate the robustness of the provided technique.
4.1 Performance Metrics
Precision, recall, F1 score, accuracy, Jaccard score, and dice coefficient are wellknown and often employed skin lesion segmentation evaluation metrics that we utilized to assess the precision with which our trained model produces segmentation results. The terminology used to describe how the metrics were calculated is listed below [18].
- 1. True Positive (TP) represents an accurately predicted lesion class label.
- 2. False Positive (FP) indicates mistakenly predicted label for lesion class.
- 3. True Negative (TN) indicates a predicted label that aligns with the actual label of a backdrop pixel.
- 4. False Negative (FN) denotes a predicted label that is mistakenly allocated to a background pixel.
Accuracy (ACC) demonstrates the proportion of correct predictions.
\[ACC = \frac{TP + TN}{TP + TN + FP + FN} \tag{4}\]
Precision is calculated by dividing the total number of real positives by the number of predicted positives.
\[Precision = \frac{TP}{TP + FP} \tag{5}\]
Recall quantifies the fraction of accurately predicted TPs.
\[Recall = \frac{TP}{TP + FN} \tag{6}\]
Jaccard index is frequently referred to as intersection over union (IoU) in the context of image segmentation. It evaluates the similarity between the predicted values y and the observed values x by comparing the individuals in two sets in order to identify which individuals are shared and which individuals are distinct.
\[Jaccard = \frac{TP}{TP + FP + FN}\] (7)
Dice Score is an equivalent numerical illustration of IoU. Additionally, it is utilized to determine if the projected mask and the reality match.
\[Dice ::::Score = \frac{2*TP}{2*TP+FP+FN}\] (8)
4.2 Performance
In this subsection, the qualitative and quantitative findings of segmentation that were collected from various in-depth experiments are provided. First, the accuracy, dice score, and Jaccard index of the proposed Dilated DenseUNet-169 are compared to those of the previously established baseline U-Net and related works. The proposed model performed exceptionally well on the ISIC 2017 data set. Table 1 displays the comparison with the baseline network.
Table 1 Summary results for all trained models.
| Models | Accuracy | Dice score | Jaccard | Recall | Precision | No. of Parameters | Model Size |
|---|---|---|---|---|---|---|---|
| Unet | 75.45% | 67.436% | 71.25% | 82.90% | 88.78% | 31,055,297 | 355.7 |
| DenseUNet-121 | 96.76% | 94.25% | 81.78% | 88.37% | 91.40% | 35,364,237 | 406.2 |
| Dilated DenseUNet-169 | 98.37% | 95.07% | 90.45% | 94.32% | 95.47% | 46,867,853 | 538 |
The results reveal that the proposed model outperformed the baseline model in terms of accuracy, dice coefficient, Jaccard index, recall, and precision. The dilated DenseUNet-169 model achieved 98.37% accuracy, 95.07% dice scores, 90.45% Jaccard index, 94.32% recall, and 95.42% precision. Meanwhile, UNet achieved 75.45% accuracy, 67.43% dice scores, 71.25% Jaccard, 82.90% recall, and 88.78% precision. In addition, we compared it with DenseNet-121. It achieved 96.76% accuracy, 94.25% dice score, 81.78% Jaccard index, 88.37% recall, and 91.40% precision. Clearly, the proposed model outperformed the baseline UNet and Dilated DenseUNet-121. These favorable findings refer to our model, which contained more parameters and was larger.
In image segmentation, the receiver operating characteristic (ROC) curve graphically illustrates the performance of a binary classifier as it adjusts the threshold for classifying a pixel as foreground or background. At various
threshold values, the ROC curve compares the true positive rate (TPR) and false positive rate (FPR). It is possible to compare the performance of various classifiers using the area under the ROC curve (AUC), which is a measurement of the classifier's overall performance.
A classifier with an AUC of 1.0 is considered to have perfect performance, while a classifier with an AUC of 0.5 is considered to have no discriminatory power. DenseUNet can segment skin lesion images to some extent; however, there are still some untapped characteristics. On the one hand, DenseUNet only distinguishes between normal skin and lesion regions and does not further classify the different types of lesions, providing insufficient data for upcoming procedures.
Figure 5 shows the quantitative AUC-ROC results for the three models (UNet, DenseUNet-121, and DenseUNet-169) with a hyperparameter batch size of 16 and a training phase learning rate (lr) of 0.0001. Finally, we applied 25 epochs to improve the accuracy and precision of all metrics. It clearly reveals the effectiveness of our segmentation model.
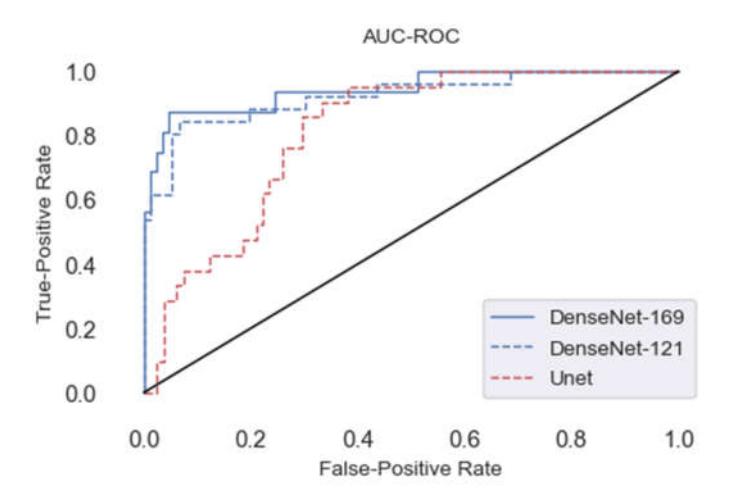
Figure 5 Comparative AUC-ROC results for three models (UNet, DenseUnet-121, and DenseUnet-169).
For further validation, we compared our method to the results of related works, as shown in Table 2. It revealed that our proposed method outperformed the previously used methods because the Dilated Dense UNet-169 network could segment skin lesions with greater accuracy and robustness than traditional CNN. This positive result demonstrates the effectiveness of our method.
| Reference | Method | Dataset | Task | Accuracy | |
|---|---|---|---|---|---|
| [13] | artificial bee colony (ABC) | ISIC2017 | Segmentation | 94.40% | |
| [19] | FC-DPN | ISIC2017 | Segmentation | 95.14% | |
| [14] | DCNN | ISIC2017 | Segmentation | 97.235 | |
| propose | Dilated DensUnet-169 | ISIC2017 | Segmentation | 98.384 | |
Table 2 Comparison results between our proposed work and related works.
Figure 6 illustrates some of our model's generated results by placing an RGB dermoscopy image with corresponding ground truth, UNet, and DenseUNet-169 generated binary masks side by side. Therefore, the provided findings show that our model accurately separated the melanoma moles and was resistant to changes in the structure of skin lesions.
Figure 6 Comparison of generated results with input and ground truth: (a) RGB dermoscopy image; (b) annotated ground truth; (c) UNet generated mask; (d) DenseUNet-169 generated mask.
4.3 Discussion
The proposed segmentation method outperformed existing methods in accuracy, dice score, Jaccard, and precision. Our model's high segmentation accuracy impacts skin cancer detection and diagnosis. First and foremost, our segmentation model's improved accuracy can help detect and treat melanoma early, improving patient outcomes and lowering mortality rates. By accurately segmenting skin lesions, clinicians can target treatments. This study also showed that dilated convolutions improve contextual information capture and receptive fields without adding parameters. This feature is beneficial to tele-dermatology applications because computational resources are limited.
The proposed model is efficient and effective for both real-time and near-realtime segmentation. Our architecture also includes the CCAB attention mechanism. This improves feature computation and focuses on salient regions, reducing false positives and improving model segmentation. The model's performance on more complex skin lesions can be improved by adding contextual cues to this attention-based approach.
This research adds to the skin lesion segmentation literature and shows the potential of deep learning models. Because it works so well, researchers can use Dilated Dense UNet-169 to look at larger datasets, different types of skin lesions, and how it works with other imaging methods like dermoscopy and histopathology. Our findings also highlight the importance of tele-dermatology research in filling dermatological care gaps, especially in rural areas. Our model's accurate and efficient segmentation can enable remote consultations, decision support systems, and automated triaging, improving dermatological expertise and healthcare disparities. Our skin lesion segmentation method is accurate and precise. Our findings improve skin cancer detection, early intervention, patient outcomes, and tele-dermatology. This research lays the groundwork for future advancements in automated skin cancer diagnosis and treatment planning.
In order to provide clinicians with useful information for diagnosis and further investigation, it is critical to do research on how to further segment the region in relation to the diagnostic criteria for the treatment of pigmented skin lesions. The setup of epochs and other hyperparameters is required for DenseNet training, which is time-consuming and usually unsuccessful. Future studies using neural network-automated search technology may automatically examine the appropriate parameters for the skin lesion image segmentation problem.
5 Conclusion
In this paper, we constructed a dilated convolutional-based network called DenseUNet-169 to segment images of skin lesions. DenseNet feature extraction blocks equip DenseUNet-169 to gather adequate context information, thereby refining the segmentation results of skin lesions. We trained and evaluated our models using the ISIC 2017 data set in our experiments. We designed the new U-Shape CCA-UNet network for dense prediction tasks. The DenseUNet-169 model incorporates the CCAB architecture in additional stages beyond the feature map, which exhibits the highest level of semantic representation.
This allows for the optimal utilization of this representation in the subsequent inference tasks. The present module integrates multi-stage and multi-scale information along the spatial axis to produce an attention map for each stage. The results showed that dilated convolution-based feature extraction blocks can extract more detailed lesion areas, making them very effective at separating skin lesions from images.