
1 Introduction
General-purpose large language models (LLMs) such as GPT, BERT, T5, and DeepSeek have advanced natural language processing (NLP) by enabling breakthroughs in machine translation, information retrieval, and text summarization [1-3]. However, when applied to religious or culturally sensitive domains, these models sometimes fall short [4][5]. Islamic studies, especially in tafsir (Quranic exegesis), Hadith authentication, and fiqh (Islamic jurisprudence), require a depth of nuance and contextual understanding that generic LLMs may lack.
This paper explains why domain-specific LLMs for Islamic studies are both necessary and timely. Models trained on general web data may misinterpret legal
texts or misrepresent key religious sources. Islamic jurisprudence demands a precise reading of canonical texts, respect for diverse schools of thought, and an ethical commitment to avoid misinformation. For example, when asked a jurisprudential question such as "Is gold liable for zakat, and what are the applicable nisab and rate?", a general-purpose LLM can produce imprecise or internally inconsistent responses: for instance, implying that zakat on gold is optional or omitting the established nisab and the standard zakat rate (commonly understood as 2.5% per lunar year). Such omissions or inaccuracies may mislead non-expert users seeking legal guidance. In contrast, a domain-adapted model trained on curated jurisprudential corpora and verified sources is better positioned to reproduce doctrinally accurate answers and supply primary citations, thereby reducing the risk of doctrinal error and improving trustworthiness [23].
Errors or biases in an Islamic LLM can directly affect religious practice and understanding. Ethical frameworks in AI, including transparency, fairness, privacy, and accountability are therefore critical [6-9]. Context-specific ethical guidelines, curated data practices, and ongoing scholarly oversight are also essential [10][11].
2 Evolution of Large Language Models
2.1 Evolution of General LLMs
The field of language modeling has progressed through several distinct generations (Figure 1). Early approaches relied on statistical methods and n-gram frequency counts to predict text, grounded in information theory. These were gradually succeeded by neural network models; simple recurrent neural networks (RNNs) and long short-term memory (LSTM) networks allowed sequential processing with some memory of context. However, RNN-based models struggled with long-range dependencies due to vanishing gradients. A breakthrough came with the introduction of the Transformer architecture by Vaswani et al. in 2017 [12].
Transformers use self-attention mechanisms to process input in parallel and capture long-distance relationships more effectively. On this foundation, a new wave of large language models emerged. For example, BERT employed a bidirectional Transformer encoder for natural language understanding [1], while GPT used an autoregressive Transformer decoder for text generation [2]. Unified frameworks like T5 recast all NLP tasks into a text-to-text format, further demonstrating the versatility of Transformers [3].
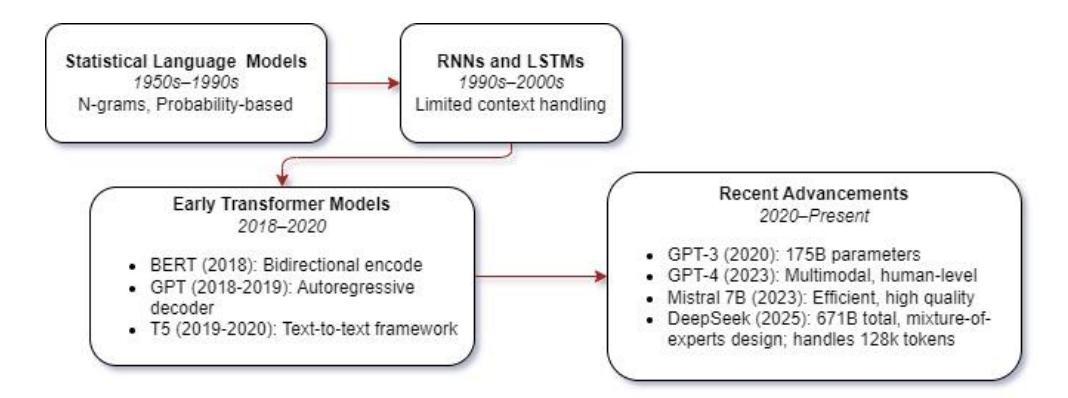
Figure 1 Timeline of the evolution of general LLMs.
As these architectures matured, model scale became a key factor. The number of parameters and training data size grew exponentially in the late 2010s and early 2020s, leading to models like GPT-3 with 175 billion parameters that exhibited emergent abilities in zero-shot learning. This scaling trend culminated in even larger and more capable models such as GPT-4, introduced in 2023, which is a multimodal model capable of processing both text and images and achieving human-level performance on many benchmarks [13].
Alongside proprietary models, open-source efforts have produced efficient LLMs. Mistral 7B, released in 2023, demonstrated that a 7-billion-parameter model can match or exceed the performance of larger models by training on highquality data [14]. At the extreme end, mixture-of-experts architectures such as DeepSeek, announced in 2025, leverage a massive parameter count (671 billion total) while activating only a subset of 37 billion parameters per query, resulting in state-of-the-art performance and context handling of up to 128k tokens [15]. These latest advancements illustrate the diverse paths in LLM evolution, from efficient small models to large-scale, innovative architectures.
Recent surveys have further highlighted the diverse applications of LLMs in domains such as healthcare, legal reasoning, and education, demonstrating the broad potential of these models when tailored for specific contexts [43][44]. Similar approaches have been adopted in other domains to improve factuality and task performance. For instance, Med-PaLM and BioGPT specialize in medical question answering [45][46], while Legal-BERT has been fine-tuned for legal text classification and contract analysis [47]. These efforts show that domain specialization significantly improves model performance on high-stakes tasks, motivating the development of equally specialized models for Islamic studies.
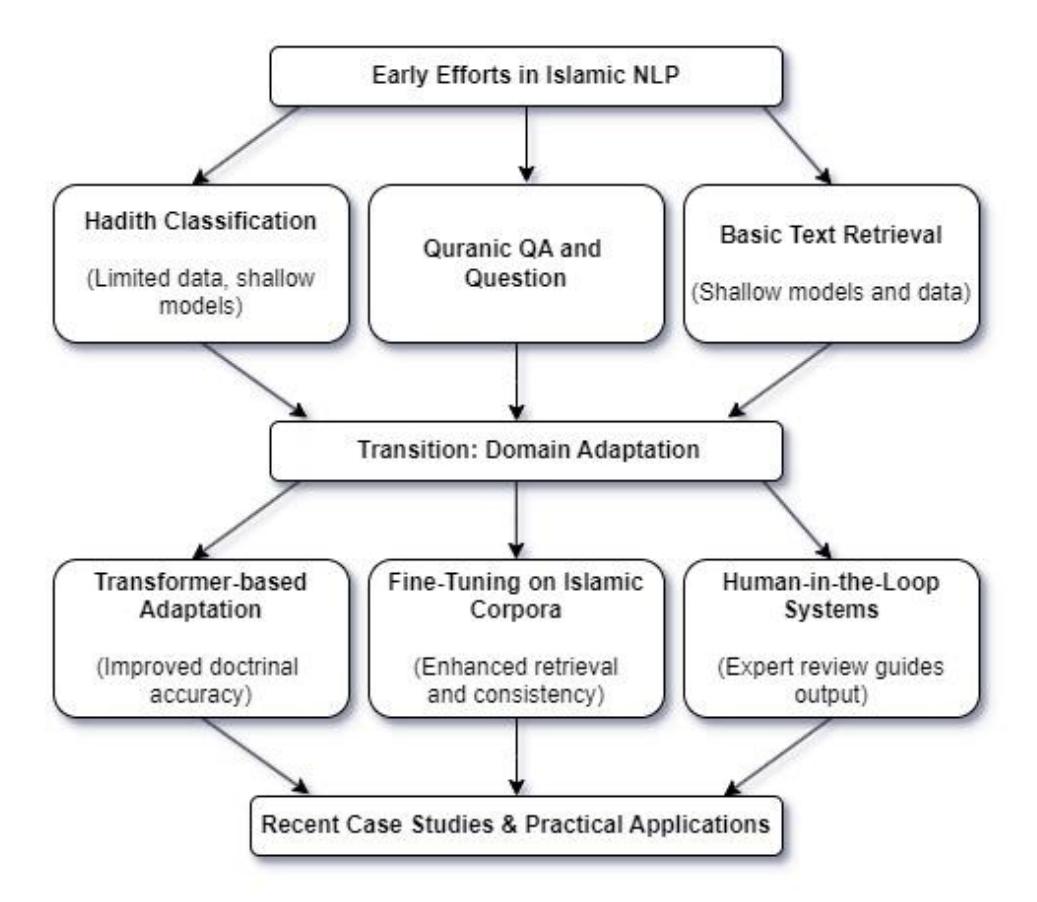
Figure 2 Evolution and practical applications of Islamic LLMs.
2.2 Evolution of Islamic LLMs
The development of LLMs tailored to Islamic studies is promising and growing rapidly. Early computational efforts applied NLP techniques to specific tasks rather than building general-purpose Islamic LLMs.
Researchers initially focused on automated Hadith classification and verification systems, as well as Quranic question-answering systems that leveraged machine learning on limited datasets [4][5]. A survey by Alnefaie et al. in [19] cataloged domain-specific QA systems for Arabic Islamic questions, highlighting the feasibility of applying NLP in this domain [16]. Early systems often used shallow models due to data limitations and focused on retrieving and organizing knowledge from canonical texts (see Figure 2).
More recent efforts have adapted modern Transformer architectures to Islamic content. Researchers have fine-tuned models like BERT and GPT on Islamic textual data to generate interpretations or answer jurisprudence questions while attempting to maintain doctrinal accuracy [17]. For example, AlZahrani and Al-Yahia [27] concluded that pretrained transformer models fine-tuned using the Islamic legal dataset, showed significant results in applying authorship attribution to Islamic legal texts. Ibrahim et al. [26] introduced computational methods for Hadith authentication by analyzing chains of narrators, while [28] explored AIbased fatwa systems that generate legal opinions under strict oversight [19][20]. In addition, community-driven efforts to digitize and annotate classical Islamic texts have begun to yield large-scale, high-quality datasets that can be used for domain-specific model training [21].
A notable recent case study is the development of a bilingual Islamic LLM for neural search, which used a multi-stage training process starting from a multilingual Transformer such as XLM-R and further pre-trained it on Islamic texts, resulting in a model that outperformed larger generic models on in-domain retrieval tasks [22]. Although these Islamic LLMs are still in early phases of development, they show promising potential to address both linguistic and doctrinal challenges, particularly when integrated with expert feedback and specialized evaluation metrics as described later. While research on Islamic LLMs has grown rapidly, public accessibility remains limited.
Most existing systems, including bilingual Islamic LLMs for neural search [22], Hadith authentication models [26], and AI-based fatwa generation systems [28], are either research prototypes or restricted to academic collaborations. None currently match the level of public availability of large general-purpose models such as ChatGPT [2] or Gemini. Nevertheless, community initiatives such as the Quranic Arabic Corpus and other open digitization efforts [29][31] are creating foundational datasets that may enable future publicly accessible, open-source Islamic LLMs. Until such models are released, access to domain-specific LLMs for Islamic studies is primarily limited to researchers and developers involved in ongoing projects. The following Table 1 provides a summary of key, prominent initiatives based on available information:
| Project / Model Name | Architecture | Primary Task | Description | Status & Accessibility |
|---|---|---|---|---|
| Quranic Semantic Embedding Search | Transformer based embeddings | Semantic search | Focused on meaning based retrieval of Quranic verses using contextual embeddings instead of keyword matching. | Research prototype; not a conversational LLM [4] |
| Bilingual Islamic LLM for Neural Search | Multilingual Transformer | Neural search & retrieval | Multi-stage training on Islamic corpora. Outperformed larger generic LLMs in retrieval tasks. | Academic case study; limited accessibility [22] |
| Hadith Authenticat ion Systems | Transformer models (BERT-based classifiers) | Chain-of narration analysis & classification | Analyzes isnad (chains of narrators) to verify authenticity, grouping narrations by reliability (sahih, hasan, daif). | Research systems; limited datasets and academic access [26] |
| Islamic Knowledge Classificati on System | Transformer based classifier (AraBERT / BERT) | Text classification & organization | Categorizes large corpora of Islamic texts into thematic categories, supporting better retrieval and annotation. | Published academic system; not publicly deployed [27] |
| AI-Based Fatwa Generation System | Fine-tuned Transformer + human-in the-loop | Fatwa draft generation & legal opinion assistance | Generates draft fatwas with citations, reviewed by qualified scholars to ensure doctrinal | Prototype under research; expert supervised use only [28] |
Table 1 Key Characteristics of Prominent Islamic LLM Projects and Prototypes.
Comparative evaluations reported in [22] show that a bilingual Islamic LLM significantly outperformed larger general-purpose models (e.g., mBERT, XLM-R) on in-domain retrieval tasks, achieving higher MRR and MAP scores. Similarly, [27] demonstrated significant improved classification accuracy when AraBERT is fine-tuned on Islamic knowledge categories compared to generic pretrained models. The systems described above represent existing implementations or prototypes. The following sections transition from reporting current efforts to outlining conceptual directions and future design considerations for Islamic LLMs.
accuracy.
3 Islamic Studies and NLP
Islamic studies are founded on a rich textual tradition comprising the Quran, the Hadith (prophetic traditions), and centuries of scholarly commentary. Fiqh
(Islamic jurisprudence) derives legal rulings from the Quran and the Hadith using principles such as qiyas (analogy) and ijmaʿ (consensus), with various schools of law (Hanafi, Maliki, Shafiʿi, Hanbali, etc.) employing distinct interpretative methods [23][24]. Hadith science involves the meticulous verification of narrations through an analysis of the chain of transmitters and the content, categorizing narrations as sahih (authentic), hasan (good), daʿif (weak), or mawduʿ (fabricated) [25]. These processes demand not only a deep understanding of classical Arabic but also contextual and theological expertise.
NLP applications in Islamic studies have been increasingly explored in recent years. One major area is Hadith analysis. Researchers have applied machine learning techniques for automated Hadith classification, grouping narrations by topic or authenticity. Methods include both content-based approaches (processing the text itself) and chain-based approaches (analyzing transmission metadata). Some systems have built narration graphs to track relationships among narrators, thereby assisting scholars in verifying authenticity [26]. For the Quran, NLP techniques have been applied to develop specialized morphological analyzers, part-of-speech taggers, and syntactic parsers tailored to Quranic Arabic, which significantly differs from modern standard Arabic. Additionally, several studies have developed systems for automatic tafsir assistance, retrieving classical commentaries relevant to specific verses.
Advances in Arabic NLP have underpinned many of these efforts. The development of Arabic-specific models such as AraBERT has resulted in improved performance on tasks like question answering, named entity recognition, and sentiment analysis compared to earlier multilingual models [28]. The availability of annotated resources such as the Quranic Arabic Corpus has further supported these applications [29]. However, while general NLP systems typically deal with open-domain language, Islamic NLP must address additional challenges. Data availability is limited due to the relatively small size of annotated Islamic texts compared to vast general-domain datasets. Moreover, many Islamic texts exhibit complex linguistic features, including honorifics and archaic expressions, which are not present in modern texts. Thus, while NLP in general can rely on large-scale, well-annotated corpora, Islamic NLP must often work with highly specialized and limited datasets. This necessitates the development of domain-specific models and benchmarks that ensure both linguistic fluency and doctrinal accuracy. In practice, most Islamic LLMs adopt encoder-decoder or decoder-only Transformer architectures similar to BERT or GPT variants, with domain adaptation performed through continued pretraining on Islamic corpora followed by supervised fine-tuning on QA, classification, and retrieval tasks [17][22][26]. Parameter-efficient techniques such as LoRA and adapters are often employed to reduce compute cost while preserving doctrinal fidelity [40].
4 Challenges and Ethical Considerations in Islamic LLMs
Building a domain-specific LLM for Islamic studies presents a unique set of technical and ethical challenges (Figure 3). A primary challenge is data scarcity and quality. Although digitization projects have made many canonical texts available, the volume of high-quality, annotated Islamic texts is modest compared to general web corpora. Many historical manuscripts remain undigitized or inconsistently annotated, particularly in the case of hadith chains where details about transmitters are crucial [30]. Moreover, while the Arabic Quran and primary hadith collections are well-represented, resources in other languages are limited, complicating efforts to create multilingual models [31]. Another significant challenge is bias and representation. General LLMs trained on internet data can absorb societal and cultural biases. In the context of Islamic texts, a model might inadvertently learn orientalist misrepresentations, favor one jurisprudential perspective over another, or reflect other demographic biases. Since Islamic scholarship is inherently pluralistic, it is ethically imperative to design models that do not privilege one interpretation at the expense of others [32]. Mitigating bias requires curating a balanced dataset representing various schools of thought and employing techniques such as adversarial training and bias regularization. It is also essential to integrate expert feedback loops so that scholars can review and correct model outputs. Doctrinal accuracy and ethical use are principal concerns. In Islamic applications, hallucinations or fabrications, common issues in general LLMs, can have severe consequences. A model that produces incorrect hadiths or misinterprets a Quranic verse could mislead users in matters of faith. To prevent this, models must be constrained to rely on verified sources and their outputs should include citations from authentic texts. Furthermore, Islamic questions often have multiple valid interpretations; a onesize-fits-all answer is unacceptable. The system should ideally acknowledge diverse scholarly opinions rather than presenting a single, definitive ruling [33].
Addressing these challenges requires a combination of technical strategies and governance frameworks. On the technical side, data scarcity can be alleviated by targeted data augmentation and domain-specific corpus expansion. For instance, synthetic data generation and expert-verified translations can enrich existing datasets. Techniques such as transfer learning and continued pre-training on domain-specific texts (e.g., using models like XLM-R further trained on Islamic corpora) have shown promise [34]. To mitigate bias, curated data and adversarial training are essential, along with periodic audits by subject-matter experts. Human-in-the-loop systems, as proposed in [30], can help refine outputs in real time [35]. On the governance side, an ethical framework tailored to Islamic AI is critical. This framework should incorporate general AI ethics principles: beneficence, non-maleficence, autonomy, justice, and explicability, along with Islamic ethical values such as maslaha (welfare) and amanah (trust). An oversight board composed of Islamic scholars and AI experts can periodically audit the system and provide guidelines for acceptable output. Transparency is also essential. End-users should be clearly informed that the model is an AI tool, with limitations and potential biases, and that final religious decisions should be verified by qualified scholars.
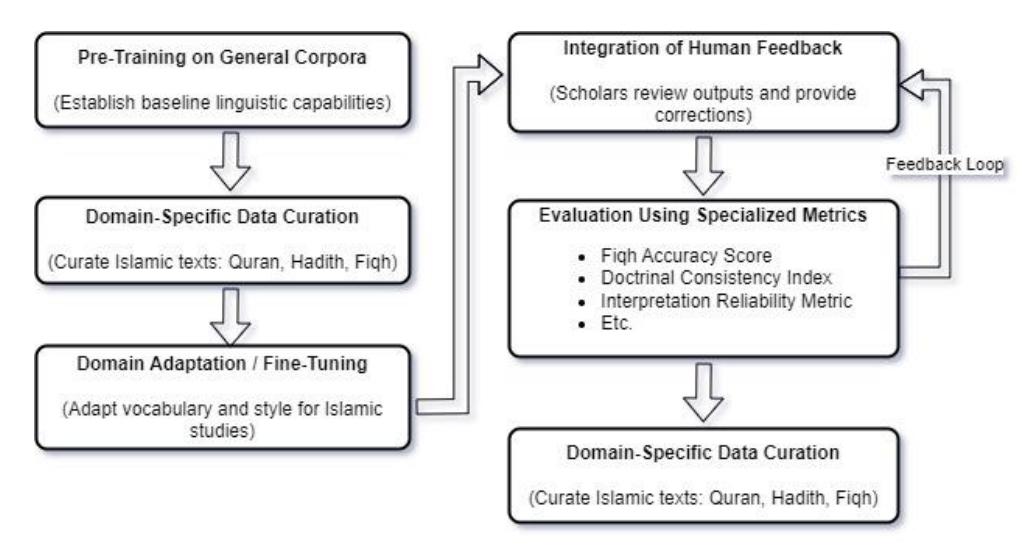
Figure 3 Workflow diagram for developing an Islamic LLM.
Addressing multilingualism is crucial, as many Muslim-majority regions rely on non-Arabic languages such as Urdu, Bahasa Indonesia, and Hausa. Current efforts include multilingual continued pretraining of XLM-R models and crowdsourced translation projects to expand parallel Islamic corpora [22][31]. Future research should prioritize building benchmark datasets across these languages to ensure inclusivity. Finally, specialized evaluation metrics, discussed in Section 5, are proposed as potential solutions to measure doctrinal fidelity and consistency. These metrics, namely Fiqh Accuracy Score, Doctrinal Consistency Index, and Interpretation Reliability Metric, can provide quantitative feedback during development and refinement. They are intended to guide future research and further testing in collaboration with Islamic scholars to ensure that the LLM's outputs meet the high standards required in religious contexts.
5 Potential Impact and Evaluation Metrics for an Islamic LLM
This section examines two interconnected aspects. First, we detail three specialized evaluation metrics designed to capture the unique requirements of Islamic textual interpretation. Second, we discuss the potential impact of an Islamic LLM on education, legal consultation, and academic research. We also
outline a validation strategy to empirically test these metrics and ensure their robustness. Finally, we also present a validation framework to ensure these metrics are empirically reliable. This section introduces a forward-looking framework. The architecture and governance mechanisms discussed here are proposed constructs intended to guide future development rather than descriptions of deployed systems.
5.1 Specialized Evaluation Metrics
Standard NLP metrics such as perplexity and BLEU [21] are widely used to assess language models. Perplexity measures how well a model predicts word sequences, while BLEU evaluates the overlap of n-grams between generated text and reference texts. Both metrics provide useful insight into linguistic fluency and surface-level similarity. However, they focus mainly on syntactic and lexical accuracy and do not capture deeper semantic meanings, doctrinal nuances, and ethical responsibilities.
In Islamic studies, texts carry layers of meaning that require strict adherence to established interpretations. An LLM in this domain must align with the doctrinal standards of various fiqh schools and respect the ethical guidelines endorsed by recognized scholars. Relying solely on perplexity and BLEU risks overlooking errors in theological accuracy or subtle interpretative shifts. This gap has led to the development of specialized metrics such as the Fiqh Accuracy Score, Doctrinal Consistency Index, and Interpretation Reliability Metric to ensure that models are evaluated on both language quality and doctrinal precision. The proposed framework is designed for interactive dialogue, enabling users to explore multiple jurisprudential opinions when ambiguity exists, rather than presenting a single static answer.
5.1.1 Fiqh Accuracy Score
The Fiqh Accuracy Score quantifies how closely a model's output aligns with established Islamic jurisprudence. It measures doctrinal alignment by comparing generated interpretations against a curated gold-standard dataset of scholarly opinions. It also evaluates contextual fidelity across various fiqh schools (e.g., Hanafi, Maliki, Shafiʿi, Hanbali) through expert ratings and automated semantic similarity measures. This score is crucial during both model training and quality assurance to ensure that outputs adhere to recognized religious interpretations [25][29].
5.1.2 Doctrinal Consistency Index
The Doctrinal Consistency Index assesses the internal coherence of an LLM's outputs across related queries. It focuses on ensuring that the model consistently
applies doctrinal principles when responding to similar or follow-up questions. The metric evaluates cross-context consistency using statistical divergence measures and expert review to verify uniformity in interpretations. Maintaining such consistency prevents contradictory or mixed doctrinal outputs and builds user trust [28][30].
5.1.3 Interpretation Reliability Metric
The Interpretation Reliability Metric evaluates the trustworthiness of the model's outputs relative to recognized scholarly opinions. It is based on expert agreement scores, where domain experts rate the generated interpretations, and on confidence scoring mechanisms that the model may internally assign. The metric also monitors longitudinal reliability to ensure that model performance remains stable over time and after updates. This dual approach provides a robust quantitative measure and guides iterative improvements [10][11][30].
5.1.4 Empirical Validation of Specialized Metrics
To ensure that the Fiqh Accuracy Score, Doctrinal Consistency Index, and Interpretation Reliability Metric are applicable and reliable, we propose a multiphase empirical validation strategy:
- 1. Gold-Standard Benchmark Creation: A balanced, multi-madhhab benchmark dataset will be curated, containing questions and answers drawn from the Quran, canonical hadith collections, and fiqh references [23][25][29]. Each item will include contextual metadata (time, place, custom) to capture jurisprudential nuance, following best practices for domain-specific benchmark construction [40].
- 2. Expert Annotation and Reliability Analysis: Multiple qualified scholars per madhhab will independently rate doctrinal alignment and contextual fidelity. Inter-rater reliability will be computed using Krippendorff's α and Cohen's κ [41], ensuring statistically robust agreement before using these annotations as ground truth.
- 3. Convergent Validity Testing: Metric scores will be compared with expert judgments and task-level performance indicators such as retrieval MRR/MAP and QA F1 [22]. Strong and statistically significant correlations will provide evidence that the metrics reflect expert judgments of doctrinal and contextual correctness.
- 4. Discriminant Validity via Ablations: Controlled ablation studies (e.g., disabling source citation, removing madhhab conditioning) will verify that the metrics are sensitive to doctrinal errors, showing measurable degradation when key fidelity-preserving features are removed [18].
- 5. Cross-Domain Generalizability: The metrics will be applied across multiple task types (tafsir retrieval, hadith classification, fiqh QA) [19][26], and across
- Arabic and English subsets to confirm that they generalize beyond a single dataset or language setting.
- 6. Temporal Stability and Drift Monitoring: Successive model versions will be re-evaluated using bootstrap confidence intervals [42] to monitor longitudinal consistency and detect regressions over time.
- 7. Iterative Human-in-the-Loop Refinement: Divergences between metric outputs and expert ratings will be systematically reviewed. Using an adaptive governance approach [30], metric definitions and weightings will be iteratively refined until alignment with scholarly judgment is maximized.
This validation approach transforms the proposed metrics into empirically grounded, reproducible measures, providing a robust foundation for continuous model development and scholarly oversight.
5.2 Impact on Education, Legal Consultation, and Research
A well-designed Islamic LLM incorporating these specialized metrics can benefit multiple areas. In Islamic education, students often seek instant clarification on Quranic verses or Hadith references. A model trained on curated texts can provide accurate context and citations, thereby supplementing traditional learning methods [35][36]. In legal or fiqh consultation, semi-automated systems could help muftis and legal experts rapidly compile relevant Quranic verses, Hadith, and scholarly opinions. To enhance scalability, expert-in-the-loop pipelines can incorporate active learning, prioritizing only the most uncertain cases for human review, thereby reducing annotation load while maintaining doctrinal reliability [30].
The Doctrinal Consistency Index ensures that legal reasoning remains uniform across interpretations, while the Interpretation Reliability Metric strengthens confidence in the outputs. These systems can also highlight minority or less-cited perspectives, fostering balanced legal guidance [37][38]. Additionally, academic researchers can use such systems for cross-school comparative studies and thematic analysis, thus bridging the gap between classical texts and modern scholarship [39]. Clear disclaimers must accompany these outputs to stress that final religious judgments remain to be validated by knowledgeable scholars [10], [11].
In addition, a representative Islamic AI oversight board is envisaged to supervise both dataset curation and model evaluation. Such a board could include scholars from each of the four major Sunni madhahib, AI ethicists, and technical experts. Decisions would aim for consensus, and where divergence persists, majority and minority positions could be documented, allowing model outputs to present multiple valid interpretations transparently. This approach would operationalize doctrinal plurality while maintaining accountability in model governance.
6 Conclusion
This paper has shown that domain-specific LLMs are necessary to address the complexity, sensitivity, and diversity inherent in Islamic studies. Generalpurpose models, while fluent, may miss crucial jurisprudential details and ethical dimensions, which can lead to misinformation. By reviewing the evolution of LLMs, detailing the intricacies of Islamic jurisprudence, and outlining the challenges in data curation and bias mitigation, we make a strong case for specialized Islamic LLMs.
Recent advances, as seen in models such as GPT-4, combine context sensitivity with improved doctrinal precision. However, challenges like data scarcity, bias, and ethical responsibility remain. Continued collaboration between AI practitioners and Islamic scholars is essential. A robust Islamic LLM with rigorous scholarly oversight could transform education, legal research, and scholarly collaboration. Future research should focus on refining methodological frameworks, developing tailored evaluation metrics (including the Fiqh Accuracy Score, Doctrinal Consistency Index, and Interpretation Reliability Metric), and validating real-world use cases through comprehensive user feedback.