
1 Pendahuluan
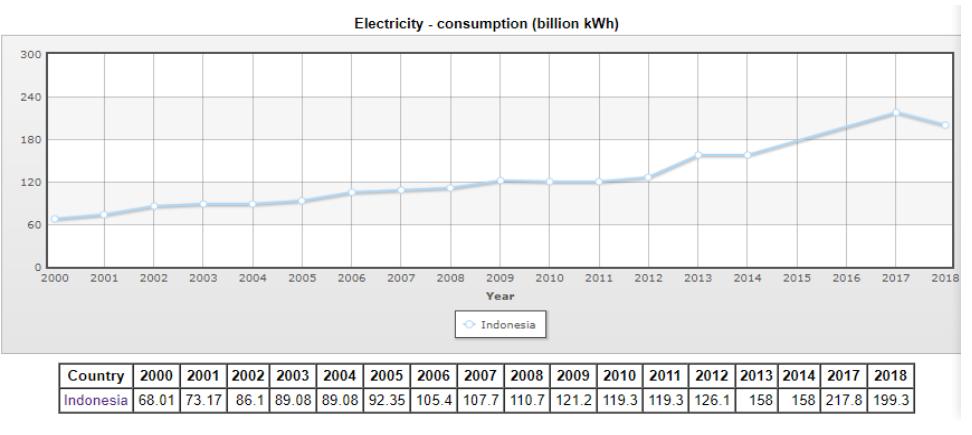
Gambar 1 konsumsi energi listrik Indonesia dari tahun 2000 - 2018
Menurut penelitian Central Intelligence Agency di US pada Tabel electricity consumption, setiap tahun Indonesia cenderung mengalami peningkatan jumlah pemakaian energi listrik yang dipakai kecuali pada tahun 2018 mengalami penurunan pemakaian listrik di Indonesia dan Indonesia menempati posisi 21 dunia pemakai listrik terbanyak di dunia dan pemerintah Indonesia dari mentri ESDM juga menghimbau untuk melakukan penghematan energi pada bulan Mei 2018 terutama penggunaan energi listrik di perkantoran pemerintah. Oleh sebab itu, diperlukan penghematan energi listrik di perkantoran terutama pada sebuah Universitas. Pemerintah juga memiliki standard IKE (Intesitas Konsumsi Energi) untuk mengukur apakah penggunaan energi listrik pada suatu ruangan atau perkantoran termasuk pemakaian yang boros atau tidak.
Tabel 1 Standar IKE Departemen Pendidikan Nasional Republik Indonesia
Oleh sebab itu diperlukan pengukuran untuk mengetahui pemakaian energi listrik pada suatu ruangan dan perkantoran. Biasanya IKE(Intensitas Konsumsi Energi) yang besar terjadi pada ruangan ber AC dan menggunakan komputer. Pada penelitian ini, pengukuran energi listrik akan dilakukan di laboratorium komputer Surya University untuk mengetahui apakah pemakaian IKE di laboratorium termasuk boros atau tidak.
2 Teori Dasar
2.1 Teori Intensitas Konsumsi Energi(IKE)
Teori tentang intensitas konsumsi energi untuk mengetahui perhitungan intensitas konsumsi energi pada suatu ruangan atau gedung. Intensitas Konsumsi Energi (Energy Use Intensity) atau IKE (EUI) berdasarkan formula perhitungan dalam Peraturan Gubernur DKI Jakarta No. 38 tahun 2012 adalah besar energi yang digunakan suatu bangunan gedung perluas area yang dikondisikan dalam satu bulan atau satu tahun. Menurut hasil penelitian yang dilakukan oleh ASEAN-USAID pada tahun 1987 yang laporannya baru dikeluarkan tahun 1992, standard IKEnya adalah sebagai berikut.
| No. | Jenis Bangunan | I.K.E (kWh/m²/th) | ||
|---|---|---|---|---|
| 1 | Perkantoran | 240 | ||
| 2 | Pertokoan (Mall) | 330 | ||
| 3 | Hotel | 300 | ||
| 4 | Rumah Sakit | 380 | ||
Tabel 2 Standard Nasional IKE bangunan
Intensitas Konsumsi Energi (IKE) listrik untuk Indonesia adalah sebagai berikut: (Direktorat Pengembangan Energi) IKE untuk perkantoran (komersil) adalah 240 kWh/m2 per tahun, pusat belanja 330 kWh/m2 per tahun, hotel/ apartemen: 300 kWh/ m2 per tahun dan untuk rumah sakit: 380 kWh/ m2 per tahun. Ini merupakan batas penggunaan konsumsi energi dapat dikatakan boros energi atau hemat energi. Sebagai contoh jika IKE (Intensitas Konsumsi Energi) di dalam gedung perkantoran (komersil) kurang dari 240 kWh/m2 maka IKEnya hemat energi. Sebaliknya jika IKE (intensitas konsumsi energi) di dalam gedung perkantoran (komeril) lebih dari 240 kWh/m2 maka IKEnya boros energi.
Intensitas konsumsi energi (IKE) pada bangunan merupakan suatu nilai/besaran yang dapat dijadikan sebagai indikator untuk mengukur tingkat pemanfaatan energi di suatu bangunan. Intensitas konsumsi energi di bangunan/gedung didefinisikan dalam besaran energi per satuan luas area pada bangunan yang dilayani oleh energi (kWh/m2/tahun atau kWh/m2/bulan).
Intensitas Konsumsi Energi (IKE) adalah istilah yang digunakan untuk menyatakan besarnya jumlah penggunaan energi tiap meter persegi luas kotor (gross) bangunan dalam suatu kurun waktu tertentu. Penggunaan energi dapat dihitung jika diketahui :
- 1. Rincian luas bangunan gedung dan luas total bangunan gedung (m2).
- 2. Konsumsi Energi bangunan gedung per tahun (kWh/tahun).
- 3. Intensitas Konsumsi Energi (IKE) bangunan gedung per tahun (kWh/m2/tahun).
- 4. Biaya energi bangunan gedung (Rp/kWh).
Perhitungan IKE (intensitas kunsumsi energi) adalah sebagai berikut:
\[IKE\left(\frac{kWh}{m^2}\right) = \frac{\text{total konsumsi energi (kWh)}}{\text{Luas lantai total (m}^2)}\] (1)
2.2 Teori Data Mining
Data mining merupakan suatu langkah dalam Knowledge Discovery in Databases (KDD). Knowledge discovery sebagai suatu proses terdiri atas pembersihan data (data cleaning), integrasi data (data integration), pemilihan data (data selection), transformasi data (data transformation), data mining, evaluasi pola (pattern evaluation) dan penyajian pengetahuan (knowledge presentation). Data mining mengacu pada proses untuk menambang (mining) pengetahuan dari sekumpulan data yang sangat besar. Data mining dapat digunakan untuk analisis data berupa eksplorasi data, pengembangan pola data, pengelompokan data, klarifikasi data dan lain-lain.
2.3 Klasifikasi Data
Klasifikasi data adalah suatu proses yang menemukan properti-properti yang sama pada sebuah himpunan obyek di dalam sebuah basis data dan mengklasifikasikannya ke dalam kelas-kelas yang berbeda menurut model Klasifikasi yang ditetapkan. Tujuan dari klasifikasi adalah untuk menemukan model dari training set yang membedakan atribut ke dalam kategori atau kelas yang sesuai, model tersebut kemudian digunakan untuk mengklasifikasikan atribut yang kelasnya belum diketahui sebelumnya. Teknik klasifikasi terbagi menjadi beberapa teknik ya ikut[2].
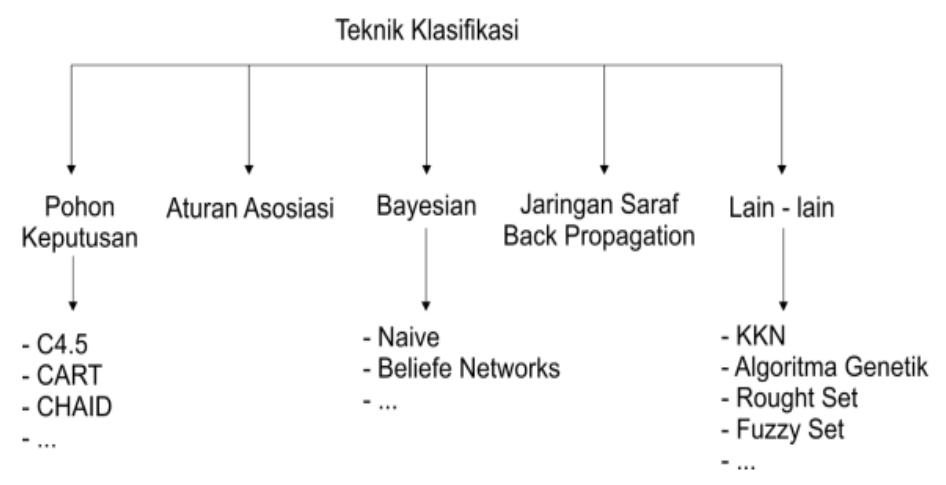
Gambar 2 Teknik Klasifikasi Sumber (Ida,2013)
Teori klasifikasi data yang akan digunakan pada analisis data adalah Teori SVM.
2.3.1 Teori SVM
Support Vector Machine (SVM) adalah suatu teknik klasifikasi yang terbilang baru. Dalam hal klasifikasi metode SVM sangat popular belakangan ini. SVM berada satu kelas dengan metode ANN (Neural Network) dalam hal fungsi dan kondisi permasalahan yang bisa diselesaikan. Keduanya masuk dalam kelas supervised learning. Baik para ilmuwan dan praktisi telah banyak menerapkan teknik ini dalam menyelesaikan masalah masalah nyata dalam kehidupan sehari hari. Baik dalam masalah gene expression analysis, finansial, cuaca hingga bidang kedokteran. Terbukti dalam banyak implementasinya, metode SVM memberikan hasil yang lebih baik dibanding metode ANN, terutama dalam hal solusi yang II 9 dicapai. ANN menemukan solusi berupa local optimal sedangkan SVM menemukan solusi yang global optimal. Tidak heran bila setiap menjalankan ANN solusi dari training selalu berbeda. Inilah yang menyebabkan ANN disebut lokal optimal karena solusi yang dicapai tidak selalu sama. SVM selalu memiliki hasil solusi yang sama untuk setiap running. Dalam teknik ini, peneliti berusaha untuk menemukan fungsi pemisah (klasifier) yang optimal yang bisa memisahkan dua set data dari dua kelas yang berbeda. Teknik ini menarik orang dalam bidang data mining maupun machine learning karena performasinya yang meyakinkan dalam memprediksi kelas suatu data baru (Budi, 2010).
Support Vector Machine (SVM) kali pertama diperkenalkan oleh Vapnik tahun 1992 sebagai rangkaian harmonis konsep-konsep utama didalam bidang pattern recognition. Secara sederhana konsep SVM dapat dijelaskan sebagai usaha mencari hyperplane-hyperplane terbaik yang berfungsi sebagai pemisah dua buah class pada input space.
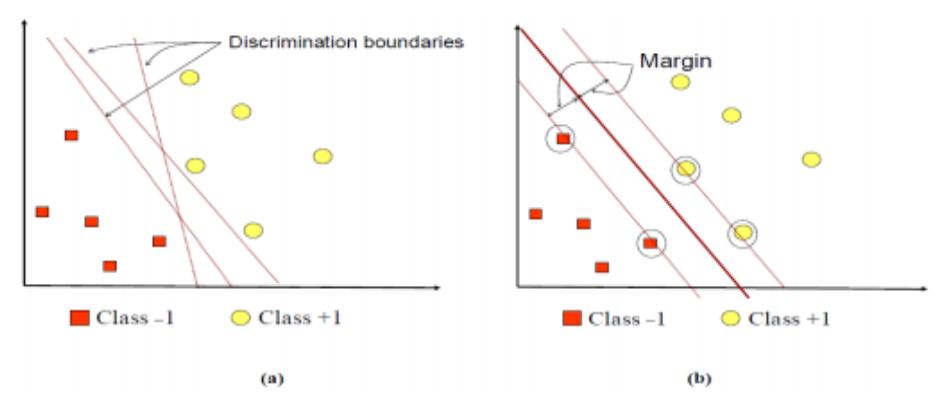
Gambar 3 Teori SVM
Gambar 3a memperlihatkan beberapa pattern yang merupakan anggota dari dua buah class : +1 dan –1. Pattern yang tergabung pada class –1 disimbolkan dengan warna merah, sedangkan pattern pada class +1, disimbolkan dengan warna kuning. Problem klasifikasi dapat diterjemahkan dengan usaha menemukan garis (hyperplane) yang memisahkan antara kedua kelompok tersebut. Berbagai alternatif garis pemisah (discrimination boundaries) ditunjukkan pada gambar 3a.Hyperplane pemisah terbaik antara kedua class dapat ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya. Margin adalah jarak antara hyperplane tersebut dengan pattern terdekat dari masing-masing class. Pattern yang paling dekat ini disebut sebagai support vector. Garis solid pada Gambar 3b menunjukkan hyperplane yang terbaik, yaitu yang terletak tepat pada tengah-tengah kedua class, sedangkan titik merah dan kuning yang berada dalam lingkaran hitam adalah support vector. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pembelajaran pada SVM. Proses pembelajaran SVM adalah untuk menentukan support vector, peneliti hanya cukup mengetahui fungsi kernel yang dipakai, dan tidak perlu mengetahui wujud dari fungsi non-linear. Persamaan SVM:
\[f(x) = w^{t} \phi(x) + b\] Dimana: \[b = \text{Bias}\] \[x = (x_{1}, x_{2}, \dots, x_{D})^{T} = \text{Variabel Input}\] \[w = (w_{0}, w_{1}, \dots, w_{D})^{T} = \text{Parameter Bobot}\] \[\phi(x) = \text{Fungsi Transformasi fitur}\] (2)
Teori SVM digunakan untuk menentukan klasifikasi data dari 2 data kelas yang ada untuk mengklasifikasi data sesuai kelas yang ada.
2.4 Teori
2.4.1 Convolutional Neural Network
CNN (Convolutional Neural Network) merupakan varian dari Multilayer Perceptron. Penelitian yang mendasari penemuan ini pertama kali dilakukan oleh Hubel dan Wiesel yang melakukan penelitian visual cortex pada indera penglihatan kucing. Banyak penelitian yang terinspirasi dari cara kerja visual cortex pada hewan dikarenakan sangat ampuh dalam pemrosesan visual dan menghasilkan model-model baru diantaranya seperti Neocognitron, HMAX, dan LeNet-5. Jenis – jenis layer yang terdapat pada CNN dapat dibedakan menjadi dua yaitu :
a. Layer ekstraksi fitur citra , terletak di awal arsitektur yang tersusun dari sejumblah layer , dimana setiap layer tersusun atas neuron yang terhubung dengan layer sebelumnya. Layer jenis pertama adalah layer konvolusi dan layer kedua adalah layer pooling atau subsampling. Setiap layer diterapkan fungsi aktivasi. Layer ini menerima input gambar lalu memprosesnya dan menghasilkan output berupa vektor Layer klasifikasi.
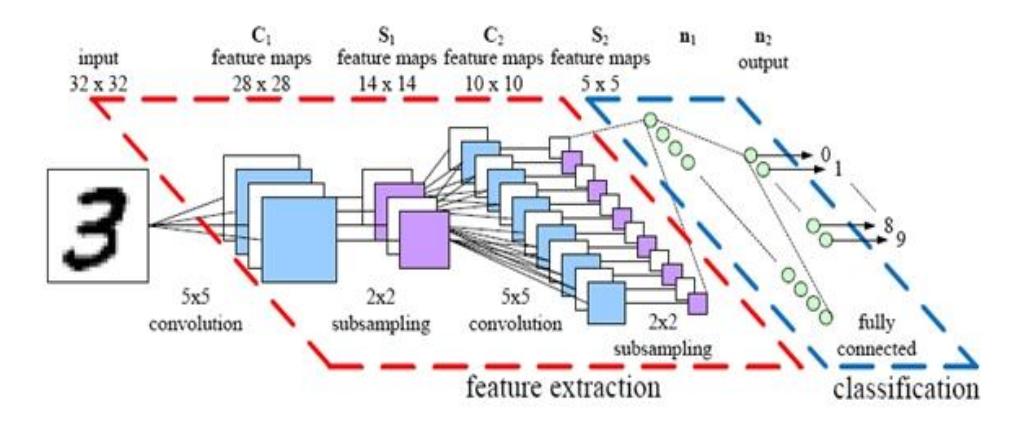
Gambar 4 Teori CNN
b. Layer klasifikasi, terdiri atas beberapa layer dimana setiap layer tersusun atas neuron yang terkoneksi secara penuh (fully connected) dengan layer lainnya. Layer ini menerima input dari hasil output layer ekstrasi fitur citra berupa vektor kemudian dengan menggunakan fungsi aktivasi softmax dihasilkan keluaran berupa skor masing – masing kelas.
3. Rancangan Sistem
3.1. Flowchart Sistem Klasifikasi Data
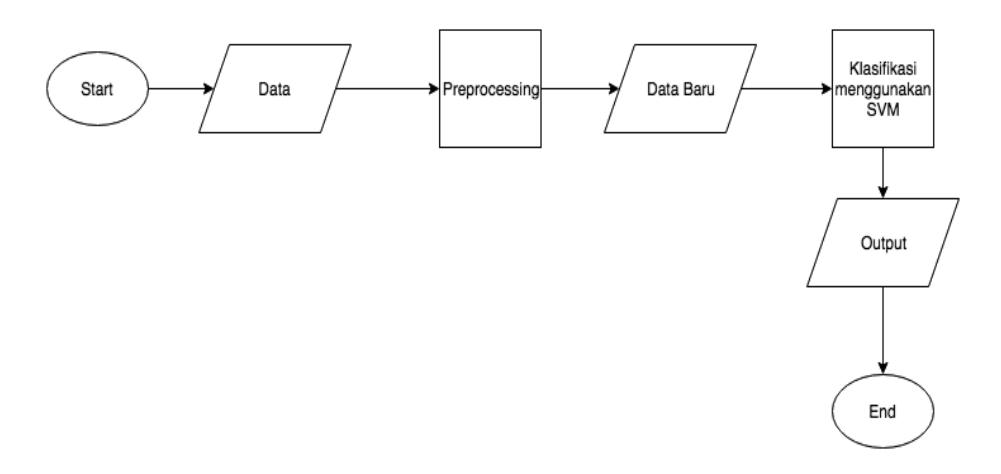
Gambar 5 Flowchart sistem klasifikasi data
Sistem yang digunakan dalam metode penelitian ini adalah pertama, dilakukan pengumpulan data daya listrik dengan mengukur daya listrik secara real time menggunakan watt meter. Pengukuran dilakukan di laboratorium komputer Universitas Surya, alat yang diukur adalah AC, lampu, dan komputer selama 1 bulan. Selain daya listrik yang diukur, luas ruangan pada laboratorium komputer Universitas Surya juga diukur untuk mengetahui luas ruangan tersebut. Setelah Data daya listrik terkumpul selama satu bulan dan luas ruangan, kemudian data di preprocessing dengan cara data tersebut di hitung untuk mengetahui daya listrik yang digunakan selama per hari dalam 1 bulan dan data daya listrik dan data luas ruangan dipakai untuk mengetahui dan menghitung IKE (Intensitas Konsumsi Energi) yang dipakai selama 1 bulan pada ruangan laboratorium komputer Universitas Surya. Kemudian setelah di preprocessing muncul data data baru yang akan diolah menggunakan teknik SVM untuk mengklasifikasikan data, setelah itu muncul output untuk mengetahui penggunaan daya listrik dalam 1 bulan yang paling paling banyak penggunaannya dan paling sedikit penggunaan daya listrik selama 1 bulan, rata-rata dan simpangan deviasi juga bisa di dapat setelah diklasifikasin datanya.
3.2. Proses Klasifikasi Data dengan SVM
Proses Ini adalah klasifikasi data dengan metode atau teknik SVM. Proses tersebut adalah sebagai berikut.
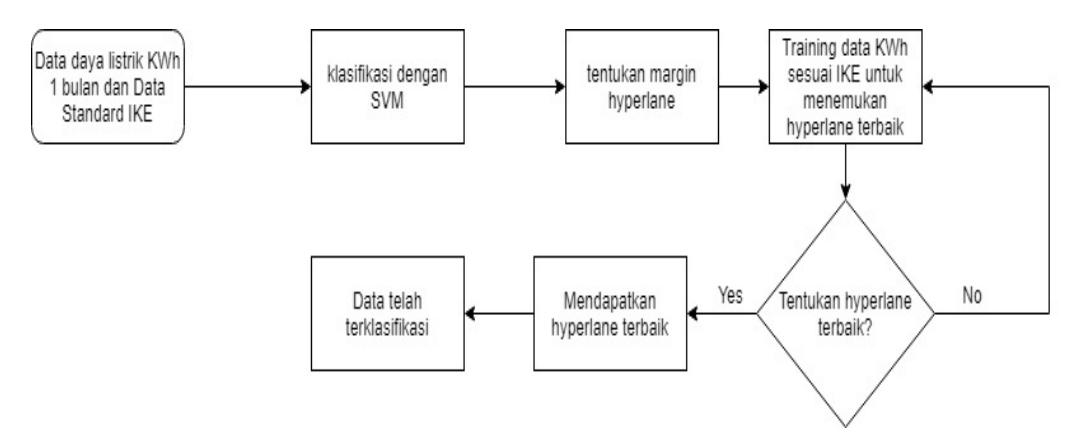
Gambar 6 Flowchart sistem klasifikasi data dengan SVM
3.3. Rancangan Perangkat Lunak
Software atau perangkat lunak yang digunakan dalam mengklasifikasikan data ini adalah dengan software WEKA.
Gambar 7 Tampilan software WEKA
3.4. Flowchart System Teknologi Smart Lab
Gambar 8 Flowchart sistem teknologi smart lab
Sistem teknologi smart lab ini adalah jika tertangkap kamera, gambar di dalam ruangan laboratorium komputer Universitas Surya tidak ada ada orang maka alat yang ada di ruangan tersebut mati secara otomatis seperti AC(air coditioner), lampu, dan komputer. Dan sebaliknya jika didalam ruangan laboratorium komputer Universitas Surya masih terdapat orang maka AC(air conditioner), lampu, dan komputer masih menyala.
3.5. Flowchart Proses CNN
Proses convolutional dimulai dengan melakukan randomisasi weight sebagai filter. Kemudian setiap piksel yang terdapat di dalam image dikalikan dengan filter. Setelah didapatkan fiturfitur baru, dilakukan proses pooling atau subsampling (penggabungan beberapa fitur menjadi satu). Kemudian dilakukan convolutional dan pooling untuk kedua kalinya. Karena fitur-fitur yang didapat terdiri dari banyak channel, maka perlu dilakukan perubahan menjadi satu array agar bisa diterima oleh Fully Connected Layer sebagai input. Selanjutnya harus dilakukan perhitungan loss, optimisasi, dan perhitungan akurasi. Setelah itu diakukan backpropagation untuk mengubah filter menjadi lebih sesuai untuk memprediksi image secara lebih baik. Hal ini terus menerus dilakukan sampai memenuhi jumblah epochs yang ditentukan.
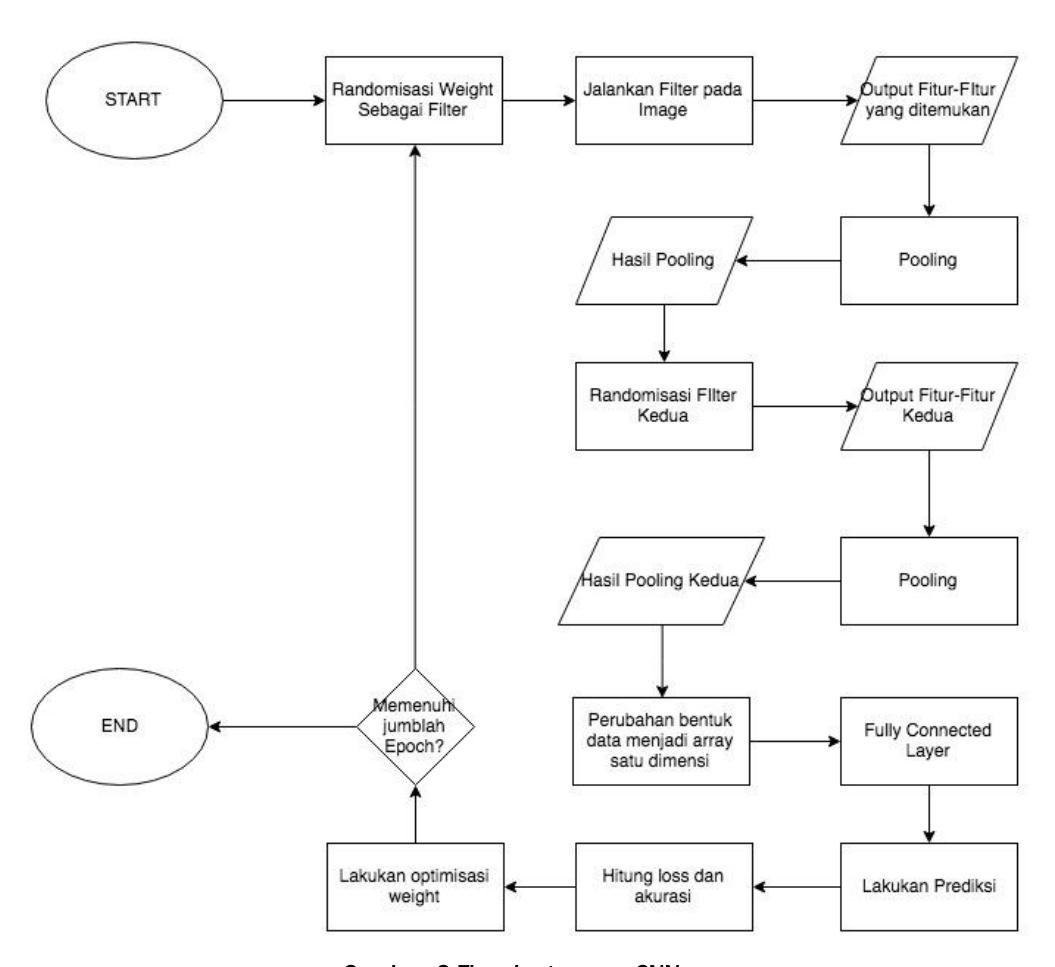
Gambar 9 Flowchart proses CNN
4. Hasil Penelitian
4.1. Hasil Pengukuran Data
Penelitian Ini adalah pengukuran dari tanggal 1 oktober 2018 – 31 oktober 2018. Sebagai Contoh data yang dimasukkan adalah data 1 minggu karena diasumsikan penggunaan setiap 1 minggu sama pada laboratorium Komputer Universitas Surya. Hasilnya adalah sebagai berikut.
Tabel 3 Pengukuran daya listrik
| Jam\Tanggal | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 08.00-09.00 | 1,209 | 1,55 | 1,523 | 46,001 | 1,209 | 1,209 | |
| 09.00-10.00 | 1,209 | 1,55 | 1,523 | 46,001 | 1,209 | 1,209 | |
| 10.00-11.00 | 1,523 | 1,55 | 1,46897 | 16,301 | 1,209 | 1,209 | |
| 11.00-12.00 | 1,523 | 1,55 | 1,451 | 1,451 | 1,209 | 1,209 | |
| 12.00-13.00 | 1,366 | 1,3795 | 1,209 | 1,209 | 1,209 | ||
| 13.00-14.00 | 43,742 | 1,451 | 1,451 | 1,209 | 1,209 | ||
| 14.00-15.00 | 43,742 | 1,451 | 1,451 | 23,605 | 1,209 | ||
| 15.00-16.00 | 22,4755 | 1,209 | 1,451 | 46,001 | 1,209 | ||
| 16.00-17.00 | 1,209 | 1,209 | 1,451 | 46,001 | 1,209 | ||
| Total KWh/hari | 117,9985 | 12,8995 | 12,97897 | 227,779 | 10,881 | 4,836 | 0 |
Tabel
Hari ke 7 penggunaan daya listrik 0 karena pada hari ke 7 adalah hari minggu dan kampus Universitas Surya tidak ada perkuliahan, oleh sebab itu tidak ada penggunaan daya listrik. Pengukuran daya listrik dilakukan secara real time dan pengukuran daya listrik disesuaikan dengan jadwal penggunaan laboratorium komputer Universitas Surya. Dari pengukuran daya listrik di komputer PC bahwa setiap software yang dipakai dalam setiap mata kuliah di laboratorium komputer Universitas Surya ternyata mempengaruhi daya listrik yang digunakan dan semakin berat /semakin banyak menggunakan processor/RAM maka komputer PC yang digunakan akan memerlukan daya listrik yang besar.
4.2. Hasil Klasifikasi data dengan SVM
Hasil Klasifikas data diperoleh dengan memasukan data-data tersebut menggunakan software WEKA dan ini adalah contoh hasil klasifikasi data dalam 1 hari. Hasilnya adalah sebagai berikut.
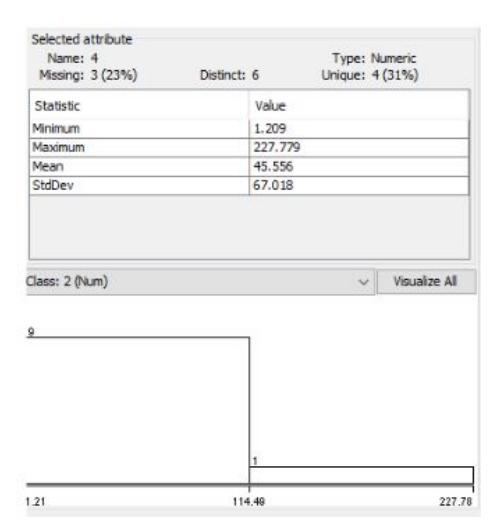
Gambar 10 Analisis daya listrik dalam 1 hari dengan WEKA
Hasil dari klasifikasi data dalam 1 hari adalah terdapat jumlah maksimum penggunaan daya listrik selama 1 hari, jadi peneliti bisa mengambil data penggunaan daya listrik yang paling besar dalam 1 hari dan dari data penggunaan daya listrik yang besar bisa peneliti analisis supaya penggunaan daya listrik bisa minimalkan atau dilakukan penghematan daya listrik, kemdian peneliti juga bisa melihat minimal penggunaan daya listrik, rata-rata daya listrik selama 1 hari, dan juga simpangan deviasi dalam 1 hari serta grafik selama 1 hari.
4.3. Hasil Preprocessing perhitungan IKE
Hasil perhitungan IKE selama 1 bulan dari tanggal 1 Oktober 2018 – 31 Oktober 2018 adalah sebagai berikut.
| Total seluruh energi | 1693,36885 | ||
|---|---|---|---|
| Luas Ruangan Lab | 20,13 | ||
| IKE | 84,12165176 | ||
Tabel 4 Perhitungan IKE
Hasil dari perhitungan IKE (Intensitas Konsumsi Energi) adalah bahwa IKE yang dihasilkan dalam 1 bulan pada ruangan laboratorium komputer Universitas Surya adalah 84,12165176 KWh dan IKE ini pada standard nasional IKE termasuk dalam kategori sangat boros penggunaan daya listrik yang digunakan selama 1 bulan pada laboratorium komputer Universitas Surya.
5 Kesimpulan dan Saran
5.1 Kesimpulan
Kesimpulan dari penelitian analisis penggunaan daya listrik di laboratorium komputer Universitas Surya sangat perlu dilakukan untuk mengetahui seberapa besar daya listrik yang digunakan dalam suatu ruangan supaya peneliti dapat mengetahui apakah dalam suatu ruangan tersebut termasuk ke dalam kategori IKE (intensitas konsumsi energi) yang boros energi atau tidak, Jika boros energi maka diperlukan penghematan energi pada suatu ruangan tersebut. Misalkan pada laboratorium komputer Universitas Surya termasuk sangat boros energi, perlu dilakukan penghematan energi pada Laboratorium komputer Universitas Surya. Penghematan Energi dapat dilakukan dengan menggunakan sistem teknologi smart lab untuk pengehmatan di dalam ruangan tersebut. Jika Laboratorium komputer Universitas Surya tidak terdapat manusia maka ruangan tersebut secara otomatis akan mati energi listriknya dan jika masih terdapat manusia di dalam laboratorium komputer tersebut maka ruangan tersebut tidak akan mati energi listriknya. Smart Lab ini tentunya dapat membantu penghematan IKE (intensitas konsumsi energi) di dalam ruangan tersebut yang termasuk dalam kategori sangat boros energi. Sistem Teknologi smart lab ini masih dalam tahap pengembangan oleh peneliti sehingga perhitungan energi efficiency menggunakan alat smart lab tersebut di dalam laboratorium Universitas Surya masih belum bisa dilakukan oleh peneliti.
5.2 Saran
Penelitian analisis penggunaan daya listrik dapat dilakukan di berbagai kampus atau ruangan lain yang menurut peneliti termasuk boros energi dan sistem penghematan energi listrik bisa dilakukan dengan metode lain atau menggunakan alat lain yang dapat melakukan penghematan daya listrik
6 Referensi
- [1] Pemborosan energi. kompas, http://kemenperin.go.id/artikel/3272/Pemborosan-Energi. Mei 2018.
- [2] Hubel, D. & Wiesel, T., Journal of Physiology (London), Receptive fields and functional architecture of monkey striate cortex, pp.195, 215– 243, 1968.
- [3] LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P., Proceedings of the IEEE, Gradientbased learning applied to document recognition. pp. 86(11), 2278–2324, 1998.
- [4] Serre, T., Wolf, L., Bileschi, S. & Riesenhuber, M, IEEE Trans, Robust object recognition with cortex- like mechanisms, Pattern Anal. Mach. Intell, Member-Poggio, Tomaso, pp. 29(3), 411–426, 2007.
- [5] Fukushima, K., Biological Cybernetics, Neocognitron: A self- organizing neural network model for a mechanism of pattern recognition unaffected by shift in position, , 36, 193–202, 1980.
- [6] Davi Oliveira et al. An autonomic system for energy cost reduction in computer labs, 2015.
- [7] Thomas Weng & Yuvraj Agarwal. From Buildings to Smart Buildings – Sensing and Actuation to Improve Energy Efficiency, 2011.
- [8] Fran Selvaggio. Four Steps for Improving Energy Efficiency in Laboratories., 2013.
- [9] Mohammed J. Zaki & Wagner Meira Jr.. Data mining and analysis fundamental concepts and algorithms. New York, Amerika: University of Cambridge, 2014.
- [10] Ivo Colanus Rally D., Metode support vector machine dan forward selection prediksi pembayaran pembelian bahan baku kopra, vol. 9, Agustus 2017.
- [11] David Barber, Bayesian Reasoning and Machine Learning., 2010.