
1 Pendahuluan
Indonesia merupakan salah satu produsen kopi terbesar di dunia [1]. Sebagai komoditas unggulan, kualitas biji kopi menjadi faktor penentu nilai jual dan daya saing di pasar global [2]. Namun, pada skala industri kecil dan menengah (IKM/UMKM), proses penyortiran biji kopi masih banyak dilakukan secara manual. Metode ini membutuhkan tenaga kerja yang cukup besar, kurang efisien, serta memiliki tingkat konsistensi yang rendah [3]. Variabilitas ukuran, bentuk, dan warna biji kopi[4]–[6], ditambah keberadaan biji cacat maupun benda
asing, semakin memperbesar potensi kesalahan dalam proses penyortiran yang pada akhirnya merugikan petani maupun pelaku usaha kopi [7].
Untuk mengatasi permasalahan tersebut, diperlukan sistem deteksi otomatis yang mampu melakukan klasifikasi biji kopi secara cepat, akurat, dan konsisten [1], [3], [4], [6], [8]–[10]. Teknologi pengolahan citra digital telah banyak diterapkan dalam inspeksi 1 kualitas produk pertanian [6], dan dalam beberapa tahun terakhir metode deteksi objek berbasis deep learning seperti You Only Look Once (YOLO) dan Roboflow Detection Transformer (RF-DETR terbukti memiliki kinerja tinggi dalam pengenalan serta klasifikasi objek secara real-time [11]. Pemanfaatan algoritma ini, jika diintegrasikan dengan platform komputasi seperti Raspberry Pi, dapat menghasilkan sistem penyortiran biji kopi yang efisien dengan variasi warna pada biji kopi dan ekonomis. Adapun harga mesin sortir konvensional biji kopi dipasaran Indonesia dapat dilihat pada Gambar 1.
Gambar 1. Desain produk sistem sortir kopi dipasaran (a) sistem sortir berdasarkan ukuran terbuat plat baja (b) Sistem sortir terbuat dari bahan kayu (Sumber : [12])
Selanjutnya untuk mesin yang dirancang untuk memisahkan biji kopi berdasarkan warna menggunakan teknologi pencitraan canggih memiliki harga yang sangat tinggi. Hal tersebut membuat pelaku UMKM untuk berfikir dua kali karena keterbatasan modal. Adapun daftar harga bisa dilihat pada Tabel 1.
Tabel 1. Daftar harga mesin dengan teknologi pencitraan [12]
| No | Nama produk | Harga |
| 1 | Mesin sortir biji kopi 2 saluran BB-R2-128 | Rp. 242.957.000 |
| 2 | Mesin pemilah biji kopi BB-TS1 | Rp. 237.984.000 |
| 3 | Mesin sortir kopi mini | Rp. 155.987.000 |
| 4 | Mesin pemisah biji kopi BB-TS4 | Rp. 377.757.000 |
Berdasarkan Tabel 1 dapat disimpulkan bahwa harga mesin sortir berbasis teknologi citra memiliki harga yang relatif mahal. Hal ini disebabkan teknologi yang digunakan serta material penyusun alat tersebut terdiri sensor yang mahal. Berdasarkan prinsip bahwa setiap warna biji kopi menyerap dan memantulkan cahaya dengan cara yang berbeda. Dengan teknologi pencitraan canggih, mesin ini mampu mendeteksi warna setiap biji kopi secara individu, lalu menggunakan kombinasi jet udara dan pelat bergetar untuk memisahkan biji kopi sesuai warnanya. Setelah itu, biji kopi yang telah dipilih akan ditempatkan pada wadah yang sesuai. Artikel ini bertujuan untuk mengimplementasikan algoritma sistem deteksi biji kopi dengan variasi warna dan tekstur berbasis model Roboflow Detection Transformer (RF-DETR)[11].
Model algoritma RF-DETR merupakan algoritma terbaru sama hal dengan algoritma YOLOv12 dalam penelitian [11]. Pendekatan sistem deteksi objek berdasarkan state-of-the-art (SOTA) dapat dibagi menjadi enam
metodologi utama sebagaimana diilustrasikan pada Gambar 2, masing-masing metode memiliki kekuatan dan aplikasi unik dalam berbagai domain teknologi dan otomatisasi. Perkembangan teknologi ini penting untuk mengatasi tantangan sistem deteksi visual secara umum di bidang yang membutuhkan presisi dan kemampuan beradaptasi tinggi. Beberapa penerapan sistem deteksi (objek detection) antara lain diterapkan pada kendaraan otonom [13], [14], layanan kesehatan [15], metode efektif dan biaya murah untuk tracking objek [16], dan khususnya di bidang pertanian [7], [17]–[20], di mana deteksi objek yang akurat dan efisien mendukung kemajuan seperti pemantauan lahan pertanian secara otomatis [20] dan pemanenan dengan robotik [17].
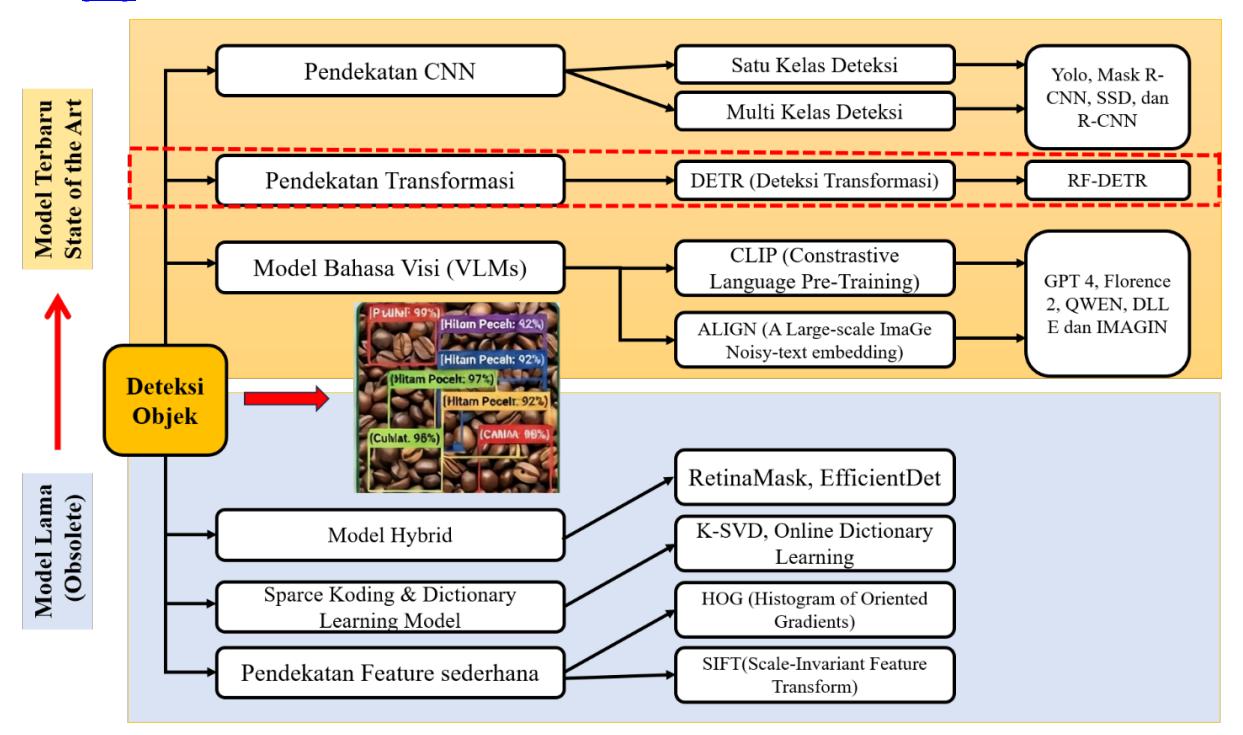
Gambar 2. Klasifikasi metodologi deteksi objek terbaru berbasis Convolutional Neural Network (CNN) dan pendekatan transformasi RF-DETR
2 Metode
Penelitian ini akan dilakukan dengan pendekatan eksperimental menggunakan metode pengolahan citra (image processing) dengan implementasi Algoritma RF-DETR melalui platform Roboflow [21]–[24]. Platform berfungsi sebagai visi komputer yang menawarkan metode yang lebih baik untuk pra-pemrosesan, pelatihan model, dan pengumpulan data, yang nantinya memungkinkan pengguna untuk membuat model visi komputer dengan lebih cepat dan tepat. Pengguna Roboflow dapat mengunggah set data mereka sendiri, membuat anotasi, mengubah orientasi Gambar, mengubah ukuran Gambar, mengubah kontras Gambar, dan memperkaya data. Keuntungan lain penggunaan Roboflow adalah memungkinkan pengguna untuk mengunggah dan mengonversi anotasi antar berbagai format dengan anotasi global yang direkomendasikan para praktisi dan akademisi. Oleh karena itu, dengan fitur dan cara tersebut, Artikel ini mencoba menerapkan Teknik pengolahan citra melalui roboflow. Adapun alur tahapan penelitian disusun secara sistematis dapat dilihat pada Gambar 3.
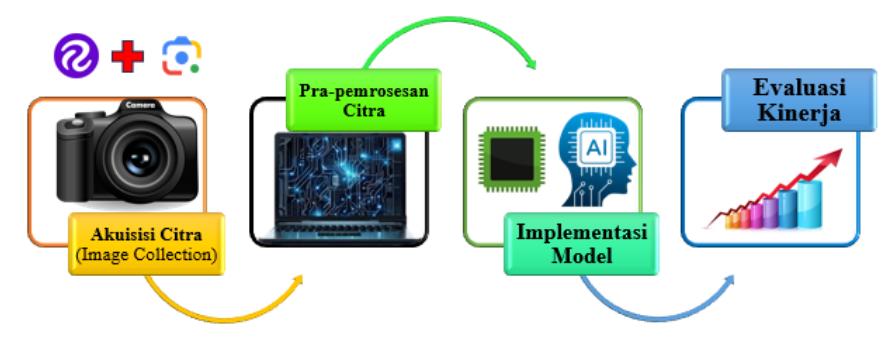
Gambar 3. Visualisasi diagram alir penelitian
Pada Gambar 3 tahap pertama adalah akuisisi citra atau pengumpulan data dimana data yang digunakan adalah citra biji kopi yang diambil menggunakan kamera digital dengan pencahayaan terkontrol (lightbox) untuk meminimalkan bayangan dan variasi cahaya. Namun pada artikel ini mengambil dari sumber data roboflow dan google image yang memiliki format data .JPG dan .PNG. Selanjutnya jumlah citra data biji kopi berjumlah 2.010 sampel.
Pada tahap 2 yaitu Pra-pemrosesan data dimana sebelum masuk ke model, data akan diproses menggunakan framework Roboflow, maka citra tersebut akan dianotasi berupa pemberian label atau bounding box pada biji kopi sebanyak 2.010 sampel citra. Adapun jumlah kelas terbagi menjadi 5 kelas yaitu biji kopi berwarna coklat 404 sampel, hitam 401 sampel, hitam pecah 402 sampel, hitam Sebagian 401 sampel dan biji kopi muda 402 sampel. Selanjutnya dilakukan Augmentasi Data yaitu teknik memperbanyak variasi data untuk mencegah overfitting berupa grayscale 15% dari total Gambar sehingga menjadi 2.398 Gambar. Kemudian dilakukan auto scale dengan ukuran Gambar menjadi 416 x 416 pixel. Adapun tujuannya membuat Gambar memiliki ukuran sama. Adapun klasifikasi dan anotasi dapat dilihat pada Gambar 4.

Gambar 4. Dataset biji kopi
Selanjutnya pada penelitian dilakukan data splitting adalah membagi dataset menjadi tiga bagian Training Set 75% bertujuan untuk melatih model. Validation Set 17% bertujuan untuk memantau performa saat training. Fungsi Utama untuk memonitor dan mengatur proses belajar mesin. Adapun cara kerja Data validasi ini digunakan selama proses pelatihan berlangsung, tetapi model tidak belajar (tidak mengupdate bobot) dari data. Data ini hanya digunakan untuk mengecek apakah model sudah pintar, atau cuma menghafal data latihan. Jika nilai akurasi di training tinggi tapi di Validasi rendah, artinya terjadi Overfitting (model cuma menghafal, tidak paham konsep). Biasanya data validasi digunakan untuk mengatur Hyperparameters seperti learning rate dan menentukan kapan harus berhenti latihan (Early Stopping) dan porsi idealnya 10%-20% dari total data. Kemudian testing dataset 8% bertujuan untuk pengujian model algoritma apakah sudah mampu belajar dengan baik dari data latih.
Pada tahap 3 berupa implementasi model algoritma dimana penelitian ini mengusulkan penggunaan RF-DETR (Roboflow Detection Transformer) yang dimodifikasi dengan backbone DINOv2. Adapun DINOv2 (Vision Transformer) berfungsi sebagai pengekstraksi fitur (feature extractor). Selain itu DINOv2 menggunakan mekanisme Self-Supervised Learning yang sangat kuat dalam memahami representasi visual umum dan khusus dari biji kopi, sehingga mampu membedakan tekstur halus antara "Hitam Sebagian" dan "Hitam Penuh". Selanjutnya Encoder-Decoder Transformer bertugas menangani hubungan antar fitur dan menghasilkan object queries. Terakhir algoritma memiliki Prediction Heads menentukan dua prediksi pertama klasifikasi berupa menentukan probabilitas jenis cacat misal: 90% Coklat. Kedua Box Head berfungsi
memprediksi koordinat kotak objek (x, y, w, h) berupa lokasi cacat. Untuk lebih jelasnya dapat dilihat pada Gambar 5.
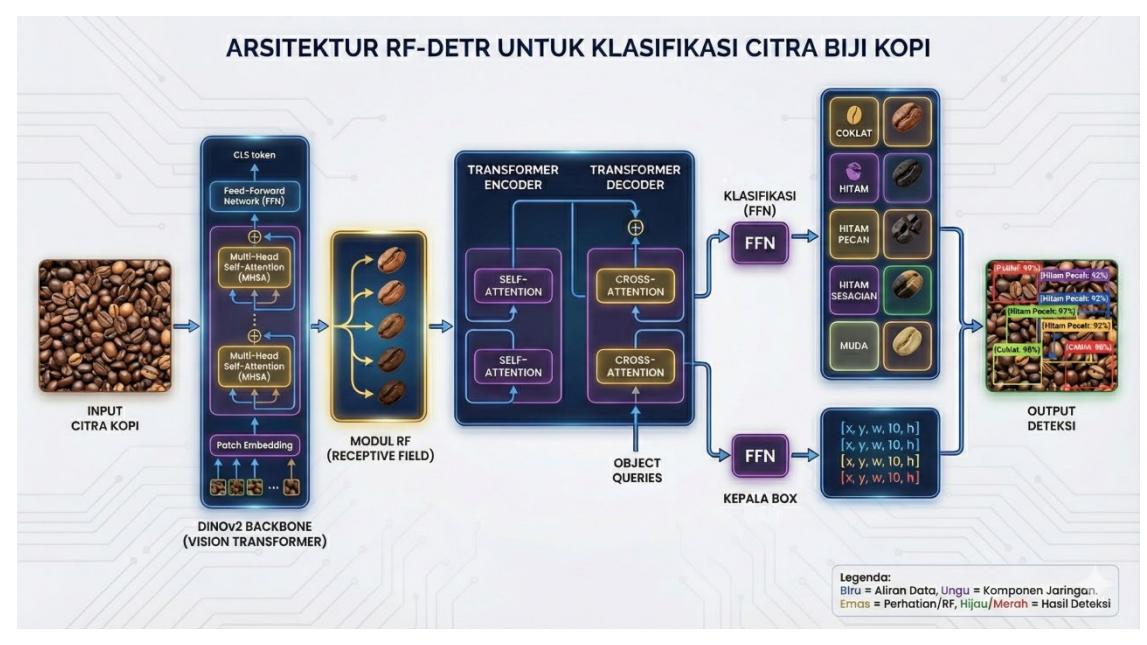
Gambar 5. Arsitektur RF-DETR untuk klasifikasi citra biji kopi
Pada tahap terakhir adalah Evaluasi Kinerja (Performance Metrics) dimana suatu algoritma suatu pembelajaran mesin dikatakan berhasil atau sukses diukur dari beberapa indikator yaitu Mean Average Precision (mAP). Selanjutnya definisi mAP 0,5 adalah akurasi rata-rata dengan ambang batas IoU (Intersection over Union) 50%. Sedangkan mAP 0,5-0,95 adalah akurasi rata-rata pada berbagai ambang batas IoU matrik paling ketat. Kemudian Precision dan Recall berfungsi untuk melihat seberapa tepat model mendeteksi cacat dan seberapa banyak cacat yang berhasil ditemukan [25]. Adapun formula untuk menilai kinerja model algoritma RF-DETR sebagai berikut.
Akurasi (mAP) = \[\frac{\sum TP + \sum TN}{\sum TP + \sum TN + \sum FP + \sum FN}\] (1)
\[Presisi = \frac{\sum TP}{\sum TP + \sum FP}\] (2)
\[Recall (Sensitivitas) = \frac{\sum TP}{\sum TP + \sum FN}\] (3)
\[F1 Score = 2 \times \frac{Presisi \times Recall}{Presisi + Recall}\] (4)
F1 Score memiliki definisi ukuran akurasi model pada dataset, yang memperhitungkan baik Presisi maupun Recall. F1 Score mengukur keseimbangan antara kemampuan model untuk tidak salah dalam memprediksi positif (Presisi) dan kemampuan model untuk menemukan semua kasus positif yang relevan (Recall).
3 Hasil dan Diskusi
Hasil penelitian dengan judul sistem deteksi cacat pada biji kopi melalui model algoritma Roboflow Detection Transformer (RF-DTER) Pra-pemrosesan data dimana sebelum masuk ke model, data akan diproses menggunakan framework Roboflow, maka citra tersebut akan dianotasi beruba pemberian label atau bounding box pada biji kopi sebanyak 2.010 sampel citra. Adapun jumlah kelas terbagi menjadi 5 kelas yaitu biji kopi berwarna coklat 404 sampel, hitam 401 sampel, hitam pecah 402 sampel, hitam Sebagian 401 sampel dan biji kopi muda 402 sampel. Selanjutnya dilakukan Augmentasi Data yaitu teknik memperbanyak variasi data untuk mencegah overfitting berupa grayscale 15% dari total Gambar sehingga menjadi 2.398 Gambar. Kemudian dilakukan auto scale dengan ukuran Gambar menjadi 416 x 416 pixel. Adapun tujuannya
membuat Gambar memiliki ukuran sama. Adapun klasifikasi dan anotasi dapat dilihat pada Gambar 6 dan Gambar 4.
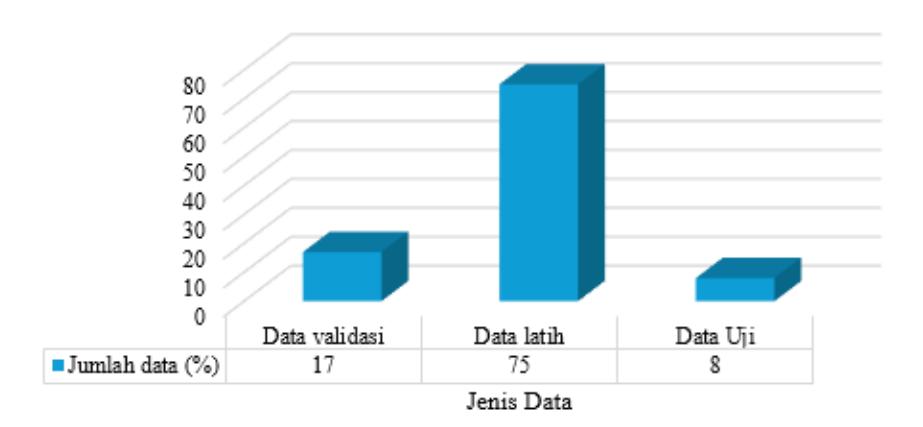
Gambar 6. Diagram batang dataset citra biji kopi
3.1 Hasil
3.1.1 Pra-pemrosesan dan Augmentasi Dataset
Penelitian ini menggunakan dataset citra biji kopi yang diproses menggunakan model algoritma Roboflow Detection Transformer (RF-DTER). Tahap awal penelitian dimulai dengan pengumpulan dan pra-pemrosesan data untuk memastikan kualitas input bagi model. Dataset awal terdiri dari 2.010 sampel citra yang telah dianotasi menggunakan framework Roboflow. Proses anotasi dilakukan dengan pemberian label berupa bounding box pada setiap objek biji kopi. Distribusi kelas pada dataset ini terbagi menjadi lima kategori cacat dan kondisi fisik, dengan rincian sebagai berikut, biji berwarna coklat sebanyak 404 sampel, biji berwarna hitam 401 sampel biji hitam pecah 402 sampel biji hitam sebagian: 401 sampel biji muda 402 sampel. Untuk mencegah terjadinya overfitting dan meningkatkan generalisasi model, dilakukan teknik augmentasi data. Teknik yang diterapkan adalah konversi grayscale sebanyak 15% dari total citra. Melalui proses augmentasi ini, jumlah total dataset meningkat menjadi 2.398 sampel citra. Selanjutnya, seluruh citra melalui proses autoscale atau normalisasi dimensi menjadi ukuran 416 x 416 pixel untuk menyeragamkan input ke dalam arsitektur RF-DTER. Adapun hasil pemrosesan seperti Gambar 4.
3.1.2 Analisis Kinerja Pelatihan (Training Loss)
Kinerja model selama proses pelatihan dievaluasi menggunakan matrik Box Location Loss. Matrik ini mengukur seberapa akurat model dalam memprediksi koordinat bounding box dibandingkan dengan ground truth (anotasi asli).
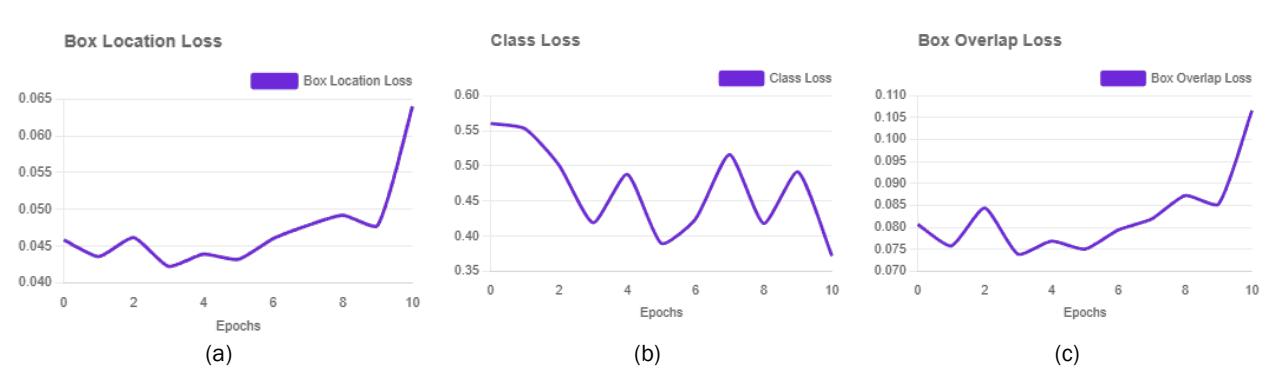
Gambar 7. Diagram garis (a) Box Location Loss (b) Class Loss dan (c) Box Overlap Loss
Pada Gambar 7 terdapat grafik Box Location Loss selama 10 epoch menunjukkan dinamika pembelajaran model. Pada fase awal, nilai loss berada di kisaran 0,045 dan secara umum menunjukkan tren yang stabil dengan fluktuasi minor di bawah 0,050 hingga epoch ke-9. Hal ini mengindikasikan bahwa model mampu mempelajari fitur lokasi objek dengan cukup baik pada tahap awal. Namun, terlihat adanya lonjakan nilai loss yang signifikan pada epoch ke-10 (mencapai > 0,060). Fenomena ini dapat diindikasikan sebagai variasi
stokastik pada akhir pelatihan atau penyesuaian bobot yang agresif pada iterasi terakhir. Meskipun demikian, nilai dasar loss yang rendah menunjukkan kemampuan lokalisasi objek yang kompetitif. Box Overlap Loss berfungsi sebagai integrasi atau mewakili oleh mekanisme yang lebih spesifik, seperti Objectness Loss atau matrik Intersection over Union (IoU) yang digunakan dalam menghitung Box Location Loss terutama Generalized Intersection over Union (GIoU).
3.1.3 Evaluasi Validasi Model
Pembahasan ini menganalisis kinerja model Roboflow Detection Transformer (RF-DTER) dalam mendeteksi cacat biji kopi berdasarkan matrik evaluasi pada dataset validasi.
No Matrik evaluasi Nilai Interpretasi 1 mAP 0,5 97,6% Akurasi rata-rata (Mean Average Precision) sangat tinggi pada threshold IoU 0.5. 2 Presisi 95,7% Tingkat ketepatan prediksi positif model sangat baik (minim false positive). 3 F1 Score 93,39% Keseimbangan harmonis antara presisi dan recall yang optimal. 4 Recall 91% -
Tabel 2. Hasil evaluasi performa model RF-DTER pada klasifikasi biji kopi
Berdasarkan Tabel 2, model RF-DTER menunjukkan performa yang sangat memuaskan dengan nilai mAP 0.5 sebesar 97,6%. Nilai ini menegaskan bahwa sistem mampu mendeteksi dan mengklasifikasikan kelima jenis cacat biji kopi dengan tingkat kepercayaan yang tinggi. Skor Presisi 95,7% menunjukkan bahwa ketika model memprediksi sebuah cacat, prediksi tersebut memiliki kemungkinan benar sebesar 95,7%. Sementara itu, Recall sebesar 91% menunjukkan bahwa model mampu mengenali sebagian besar biji kopi yang ada dalam citra tanpa banyak melewatkan objek (minim false negative). Apabila mau melihat model kinerja dapat melihat Gambar 8.
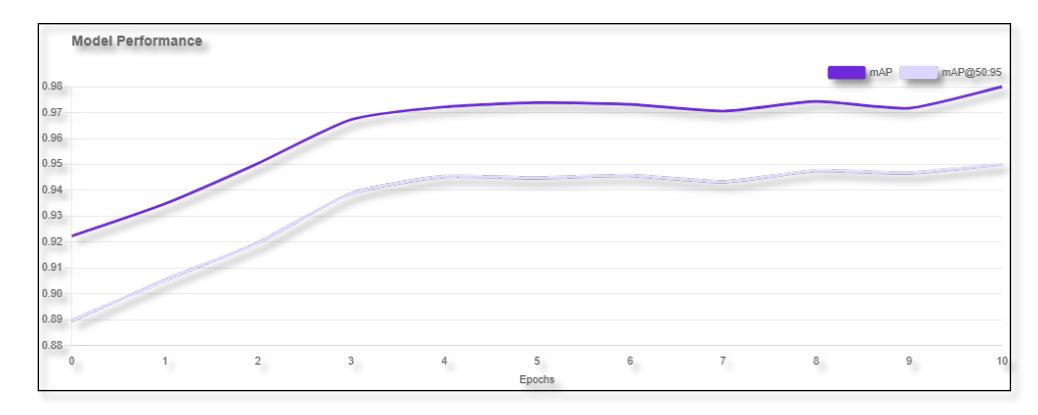
Gambar 8. Model performa kinerja
Gambar 9. Citra biji kopi yang sudah diberi label
Pada Gambar 9 merupakan citra biji kopi yang telah di anotasi, selanjutnya citra yang memiliki keseragaman dilanjutkan untuk menerapkan model RF-DETR. Selanjutnya untuk hasil deteksi objek dapat dilihat pada Gambar 10 di bawah ini. Secara umum hasil deteksi objek memiliki nilai diatas 90%.
Gambar 10. Hasil deteksi citra
3.2 Diskusi
Berdasarkan hasil evaluasi pada Tabel 1, model RF-DTER menunjukkan kinerja deteksi yang sangat baik dengan nilai mAP 0,5 mencapai 97,6%. Namun, terdapat fenomena menarik yang perlu dianalisis lebih lanjut, yaitu adanya selisih (gap) antara nilai Presisi (95,7%) yang lebih tinggi dibandingkan dengan nilai Recall (91%).
Dalam konteks deteksi cacat biji kopi, disparitas ini memberikan wawasan mendalam mengenai karakteristik model dan dataset antara lain. Pertama karakteristik model yang konservatif artinya nilai presisi yang tinggi (95,7%) mengindikasikan bahwa model memiliki tingkat "kepercayaan diri" yang tinggi saat memprediksi label positif. Model sangat jarang melakukan kesalahan false positive (menganggap biji sehat sebagai cacat, atau salah jenis cacat). Artinya, ketika sistem mengatakan sebuah biji adalah "Hitam" atau "Pecah", kemungkinan besar prediksi tersebut benar. Selanjutnya membahas nilai Recall yang lebih rendah (91%) menandakan adanya insiden false negative yang lebih tinggi, di mana model gagal mendeteksi objek cacat yang sebenarnya ada. Beberapa faktor morfologis biji kopi yang kemungkinan menjadi penyebab hal ini antara lain adalah Kemiripan Fitur Antar-Kelas (Inter-class Similarity) artinya terdapat ambiguitas visual yang tinggi antara kelas "Biji Hitam" dan "Biji Hitam Sebagian". Pada sudut pengambilan Gambar tertentu, biji yang hanya hitam sebagian mungkin terlihat seperti biji normal atau sebaliknya terlihat seperti hitam penuh jika bagian yang sehat tertutup. Model mungkin memilih untuk tidak mendeteksi (no-detection) daripada salah tebak, yang menurunkan skor Recall. Selanjutnya adalah kompleksitas Kelas seperti "Hitam Pecah": Kelas ini menggabungkan fitur warna (hitam) dan geometri (pecah). Jika retakan pada biji tidak terlihat jelas karena resizing Gambar ke 416x416 pixel atau tertutup bayangan, model mungkin gagal mengenali fitur "pecah" tersebut, sehingga objek terlewatkan.
Penerapan augmentasi grayscale sebanyak 15% seperti disebutkan dalam metodologi memiliki dampak ganda. Di satu sisi, teknik ini membuat model lebih robust terhadap perubahan pencahayaan. Namun, dalam kasus klasifikasi biji kopi yang sangat bergantung pada warna (misalnya membedakan "Coklat" normal dengan "Hitam" atau "Muda"), hilangnya informasi warna pada data latih grayscale dapat menyebabkan model kesulitan membedakan gradasi warna pada kondisi batas (boundary cases). Hal ini berpotensi menyebabkan model melewatkan biji dengan cacat warna yang samar (menurunkan Recall). Faktor berikutnya dalam proses pengolahan citra adalah pencahayaan atau lighting yang cukup. Hal ini sangat penting karena untuk membaca deteksi tekstur morfologi biji kopi jika dilakukan resizing.
4 Kesimpulan dan Saran
Berdasarkan hasil penelitian dan pembahasan mengenai implementasi algoritma Roboflow Detection Transformer (RF-DTER) untuk deteksi cacat pada biji kopi, dapat ditarik beberapa kesimpulan bahwa model RF-DTER terbukti efektif dalam melakukan klasifikasi dan lokalisasi cacat pada biji kopi. Dengan penggunaan input citra berukuran 416 x 416 pixel dan augmentasi grayscale sebesar 15%, model berhasil mengenali lima kelas variasi (Biji Coklat, Hitam, Hitam Pecah, Hitam Sebagian, dan Muda) dengan performa tinggi. Hal tersebut dapat dilihat pada kinerja model. Berdasarkan evaluasi validasi dataset, model mencatatkan nilai Mean Average Precision (mAP) pada threshold 0,5 sebesar 97,6%. Nilai ini mengindikasikan bahwa sistem memiliki tingkat akurasi rata-rata yang sangat baik dalam memetakan bounding box terhadap ground truth. Selanjutnya evaluasi matrik model ini menunjukkan karakteristik presisi yang dominan dengan nilai Presisi 95,7% dan F1-Score 93,29%. Hal ini menunjukkan bahwa sistem sangat handal dalam meminimalkan prediksi positif palsu (False Positive). Namun, nilai Recall (Sensitivitas) sebesar 91% mengindikasikan masih adanya tantangan minor dalam mendeteksi seluruh objek cacat, yang kemungkinan disebabkan oleh ambiguitas fitur visual antara kelas 'Hitam' dan 'Hitam Sebagian'.
Penelitian berikutnya guna meningkatkan performa sistem dan memperluas cakupan penelitian di masa mendatang, penulis mengajukan beberapa saran seperti Peningkatan Resolusi Input Citra disarankan untuk meningkatkan resolusi input citra di atas 416 x 416 pixel (misalnya 640 x 640 pixel). Resolusi yang lebih tinggi diharapkan dapat memperjelas fitur morfologis mikro, khususnya pada kelas 'Hitam Pecah' yang membutuhkan detail tekstur lebih tajam. Penyeimbangan variasi dataset perlu dilakukan penambahan variasi data latih (augmentasi geometris seperti rotasi atau flip) khusus untuk kelas yang memiliki tingkat kemiripan tinggi (inter-class similarity), guna meningkatkan nilai Recall. Penelitian selanjutnya disarankan untuk menguji model pada perangkat edge computing (seperti Raspberry Pi atau NVIDIA Jetson) untuk memvalidasi kecepatan inferensi (FPS) dalam skenario penyortiran industri nyata.
Ucapan Terima kasih
Penulis mengucapkan terima kasih kepada Program Penelitian BIMA 2025 yang mendanai penelitian ini dengan nomor kontrak hibah : 1483au/IT9.2.1/PT.01.03/2025 dan LPPM ITERA.