
ABSTRAK
Bahasa Inggris dianggap sulit karena berbeda dengan bahasa Indonesia baik dalam pengucapan maupun penulisannya. Walaupun demikian, di Indonesia buku-buku teks berbahasa Inggris banyak digunakan di berbagai program studi termasuk di bidang radiologi. Oleh karena itu, banyak mahasiswa mendapatkan kesulitan untuk mengerti dan memahami buku-buku berbahasa Inggris tersebut karena keterbatasan pengetahuan Bahasa Inggris mereka terutama berkaitan dengan kosakata dan gramatika bahasa Inggris. Penelitian ini bertujuan untuk mengetahui fitur linguistik dalam bentuk kosakata dan gramatika yang digunakan dalam buku Radiographic Positioning and Related Anatomy. Buku ini merupakan buku yang wajib dipelajari mahasiswa di Program Studi Radiologi. Penelitian ini menggunakan metode gabungan antara kuantitatif dan kualitatif. Dengan menggunakan perangkat lunak konkordansi AntConc data dianalisis secara kuantitaif untuk mendapatkan daftar kata berdasarkan kekerapannya. Selanjutnya, metode kualitatif diaplikasikan untuk menganalisis dan menjelaskan data yang dihasilkan. Analisis kuantitatif dan kualitatif tersebut menghasilkan daftar kosakata, kelas kata, dan pola kalimat yang sering muncul dan akan digunakan untuk menyusun kamus mini buku tersebut. Keberadaan kamus ini diharapkan dapat membantu mahasiswa radiologi untuk memahami terminologi radiologi dan memahami banyak teks radiologi secara mandiri dengan mudah. Lebih lanjut lagi, mahasiswa tidak hanya mampu memahami banyak teks radiologi tetapi juga mampu memproduksi teks, bahkan berdiskusi tentang radigrafi dalam bahasa Inggris secara madiri. Hasil penelitian menunjukkan perangkat AntCont telah memberikan manfaat kepada peneliti karena perangkat ini telah mampu membantu peneliti untuk mempersiapkan informasi leksikal dan gramatikal bahasa Inggris yang terdapat pada buku radiologi di atas. Kata Kunci: antconc, ciri linguistik, linguistik korpus
INTRODUCTION
Prior to this study, there was a survey to radiography students using the Textbook of Radiographic Positioning and Related Anatomy. The survey was conducted by giving questionnaires to identify features of linguistics considered to be difficult for students in learning and understanding the textbook. The method used to analyze the questionnaire was a quantitative method. The questionnaire was then processed to find out obstacles
faced by the students when they were reading and studying the book. Results of the questionnaires indicated that students had difficulties in understanding the book due to their limited knowledge of vocabularies, prepositions in particular, and structures of English sentences used in the book.
The findings are in accordance with Hasan (2000) stating that the difficulty faced by many learners of English as a foreign language is the difference between the pronunciation and writing of words in English. Meanwhile, Megawati (2016), through her research, found that the lack of English vocabulary often made students difficult to speak English.
Recently, corpus linguistics (CL) is widely used in many researches due to its characteristics. According to Biber, Conrad, and Reppen (1998) there are four main characteristics of corpus linguistics. Corpus linguistics is empirical and very dependent on computer performance (using specific devices). Furthermore, it uses big data in the form of electronic text and depends on quantitative and qualitative analysis techniques. One of the most fundamental ways of conducting corpus-based analysis is frequency (Baker, 2010). It refers to the number of occurrences of a word in a corpus or text. Baker (2010) also added that unlimited frequency is not only used to calculate occurrences in single words, but it is also possible to calculate grammatical, semantic, or other categories of frequencies. Through the information, the productivity of a word in a text or collection of texts can be seen. Another technique in corpus linguistics is concordance. According to Sinclair (1991), concordance is a collection of word from its occurrences in each textual environment. It displays every occurrence of the search word in each Key Word In Context (KWIC).
Meanwhile, Michael Barlow (2004) gave the definition of concordance as the transformation of a text that allows people who analyze them to see the text from a different perspective.
Previous studies related to corpus linguistics have been conducted by Svenja, et.al (2004) on the application of CL in a health care context, Rodrigo (2018) using textbooks as national teaching instruments of ESL as his research resource, and Steven (2017) on the application of CL in legal interpretation. The application of AntConc in Corpus linguistics study to observe the radiological terminologies in a radiological book has not been found yet.
The interaction between computer processing data and linguists interpreting them provides enormous benefits in a language research. By using concordance software, the corpus or corpora provides many benefits to the world of language, both in teaching and research. One of the software helping the language development was produced by Oxford that initiated the first concordance software in 1981 (Hockey&Martin, 1987). After that, many concordancers were built with their own specification. In 2002, Anthony Laurence, a professor in Waseda University Japan, built his own concordancer called AntConc. AntConc is a concordance software that can be downloaded freely and has multiplatform tools for carrying out corpus linguistics research and datadriven learning (Laurence, 2005).
This study aimed to find out how AntConc can provide linguistic features at the syntactic level with regard to vocabularies (word classes) and grammar (syntactical) that appear and are used in the textbook. Results of the research in the form word list and grammatical rules will be used to compile a pocket dictionary of Radiographic
Positioning and Related Anatomy Textbook. Therefore, in addition to being able to learn and understand the Radiographic Positioning and Related Anatomy textbook, the vocabulary and grammar obtained from the book will also help radiography students to be able to learn and understand many other English radiological sources such as international magazines or journal articles autonomously as well as be able to write and communicate especially in the field of radiology.
METHOD
The source of data used in this study is a radiology textbook of Radiographic Positioning and Related Anatomy written by Bontrager and Lampignano. The book is used as a compulsory textbook at Radiology study program of Politeknik Al Islam since the first semester of the study. This book contains 826 pages which are divided into 20 chapters explaining the basic principles of radiography and imaging, as well as the anatomy associated with radiographic processes.
The method used in this study was a mix method of quantitative and qualitative. The quantitative method was used at the initial step of the research by using AntConc to get descriptive statistic data showing word lists containing lexical information sorted by their frequency. In analyzing the textbook quantitatively, this study utilized some of the AntConc tools of Word List to count and list all words in the textbook by frequency or word, Concordance to see how words are used, Cluster to group the search words by their similarity, and file view to display the search terms in individual and original file. After that, the qualitative method was used to syntactically analyze the wordlists having been sorted by word classes to get the general linguistic features attached to each word class. To meet the B1 level of CEFR, the words to be analyzed syntactically was limited only the first 3250 words from the word list.
RESULTS AND DISCUSSION
AntConc has successfully generated a list of vocabularies sorted by their occurrences. The results show that the book is composed of 12395 types of words with the total words of 428117 including the repeated words in the textbook. Of the 3250 words being classified by word classes, there are 1717 nouns, 619 main verbs, 636 adjectives, 100 adverbs, 29 prepositions, 18 conjunctions and 9 pronouns. The percentage of each word classes is presented in the following pie chart.
Lexically, noun has the biggest part of the pie showing the highest total of words occurring in the text. Image,
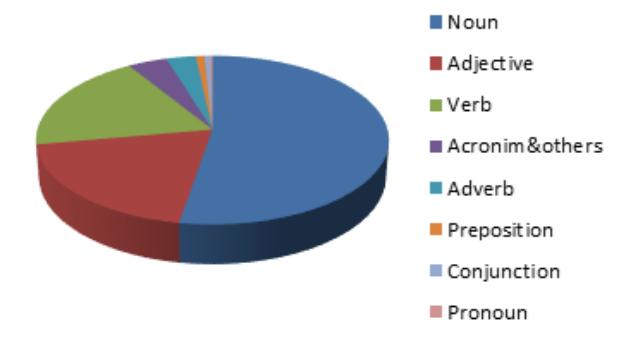
Chart 1 Classification Results by Word Classes
TABLE I GRAMMATICAL FEATURES USED IN THE TEXTBOOK
| NO | GRAMMATICAL FEATURES |
|---|---|
| 1 | Simple, compound, complex, compound complex sentences |
| 2 | Active and Passive voice |
| 3 | Tenses: simple present tense, continuous tense, past tense, present perfect |
| 4 | Comparative and superlative adjectives |
| 5 | Coordinate, subordinate, and correlative conjunction |
| 6 | Modal Verbs |
| 7 | Relative Clause |
| 8 | Reducing Relative Clause |
| 9 | Definite and indefinite article |
| 10 | Countable and countable |
| 11 | Subjective, objective and possessive pronoun |
patient, position, exposure, joint, contrast, projection, imaging, body, bone, inches, anatomy, collimation joints, spine, part, rotation, interest, bones, system are samples of nouns taken from the first 20 nouns occurring by frequency. The linguistics features found in the noun list are common and proper noun, countable and countable nouns, the use of articles a, an and the. In the opposite, there is also pronoun including subjective, objective, and possessive pronouns having the lowest frequency.
The most common verbs occur in the text are is, be, are, may, should, and can, which belong to the auxiliary verbs. The verbs to be, as the auxiliary verbs, are mostly used to form passive sentences. Samples of the lexical verbs are demonstrated, include, shown, recommended, performed, seen, placed, ensure, called, taken, described, required, been, located, centered, study, demonstrate, collimate, visualized, lead, support, being, including, needed. There are four form of verbs; base form, verb –ing, past form, and past participle. Syntactically, each verb form shows their grammatical features some of which related to the tenses and clause. Many verbs occur in base form display simple present tenses. However, not all -ing
verbs form is used in present continuous tense. Some of – ing verbs are used to write reduced clauses and others are used as adjectives modifying nouns and forming noun phrases. Most of verbs occur in the past participle forming passive sentences, present perfect tense, and as adjectives modifying nouns. Only some of past verbs are used.
There are 636 adjectives such as axial, proximal, common, other, possible, superior, large, perpendicular, both, long, cervical, thoracic, bony, inferior, medial, minimum, and vertebral. The function of the adjectives in addition to modifying nouns that form noun phrase, some of them also become the complement of verbs to be. This study also found some adjectives in the form of – ing verb and past participle. There is also the use of comparative degree with suffix –er and – est and the use of the word 'more' and ' most'.
100 adverbs are found in the list of 3250 words. They, among others, are generally, usually, commonly, slightly, very, directly, especially, caudad, frequently, upright, cephalad, posteriorly, anteriorly, and laterally.
Samples of prepositions are of, to, in, for, with, on, by, from, at, and into. Meanwhile, kinds of conjunction
found in the word list are coordinate conjunctions such as and, or, but, subordinate conjunctions such as which, when, where, whenever, whose, that, and correlative conjunctions such as also, only, either, and unless. In addition to those lexical and functional words, there are also found acronyms such as Fig, IR, CR, AP, cm, and PA and some single letters. The summary of the grammatical features is shown in Table 1.
Results of the quantitative analysis performed by word list tool of AntConc that generated the word list by frequency allow the researcher to sort and classify the words by their word classes easily. The classification of the words by frequency and then by word classes is important because the results of the classification will help radiography students to determine which nouns, verbs, adjectives or adverbs should be understood and memorized first especially those words that are closely related to the radiography process. Moreover, it also will inspire the researchers to decide the way to present those words in the pocket dictionary to be compiled.
Through the concordance, cluster / N-grams and file view tools of the AntConc the researchers are able to analyze the search words qualitatively. By knowing the grammatical rules attached on each verb, besides being able to comprehend the texts in the book, students are hoped to be able to comprehend other English radiological sources such as magazines or journal articles. Furthermore, based on the syntactical information given in the pocket dictionary students can produce their own texts and used them in the spoken and written communication.
Providing lexical and syntactical information of the Textbook of Radiographic Positioning and Related Anatomy does not only help students in understanding the book easily and autonomously but it indirectly also helps all radiography lecturers in teaching since the book underlies all the process conducted in the radiography processes.
CONCLUSION
Using word list tool, AntConc has successfully conducted the quantitative analysis generated the descriptive data of all words used in the textbook that were sorted by frequency. The data show that there are 12395 different words and 428177 words in total used in the books. The first 3,250 words from the word list were then classified and it generated 1717 nouns, 619 verbs, 636 adjectives, 100 adverbs, 29 prepositions, 18 conjunctions, and 9 pronouns. Besides, there are 132 words belonging to acronyms and others. At the syntactical level, the AntConc tools of concordance, cluster/n-grams, and file view assist the researchers to analyze the descriptive data qualitatively. The tools display the search term in concordance line to see the keywords in context, group the words by their similarities, and show each search term in individual text. All of them ease the researchers to observe each word and conclude the grammatical features attach on each word in each word classes.
The results of this research in the form of vocabulary list and grammatical rules relating to the radiology field will then be used to compose a pocket dictionary of the textbook of Radiographic Positioning and Related Anatomy, which will become the first pocket dictionary of the textbook. The dictionary can assist the students to memorize many common radiological terms. Therefore, they will understand not only the textbook but also radiological journal articles and other radiography books. Having the vocabularies and grammatical knowledge, they are also able to use the vocabularies in written and spoken communication concerning to radiography field at particular. Therefore, it can be concluded that AntConc has benefited the researchers in providing the needed lexical and syntactical information. However, further research is needed to observe the radiological textbooks in preparing ESP modules for teaching English as the foreign language.